ELK 를 5-노드 K3s 홈랩에 깐다 — hot/warm/cold 3-노드 ES + Fluent Bit + Telegram 알람
5 노드 K3s 홈랩에 운영중인 24+ 네임스페이스의 컨테이너 로그를 한 곳에 모아 검색·분석·알람까지 받을 수 있도록 ELK 스택을 통째로 GitOps 로 배포한 기록입니다. Loki 가 깔려있다고 메모리에 적혀있었는데 막상 들어가 보니 클러스터 스코프 로그 집계가 없었고, “메트릭은 있지만 로그가 없는” 관측 공백을 ELK 로 채웠습니다.
이 글에서 다루는 것
- 5-노드 홈랩(르무엘/일원/솔로몬 master + 루이스/데이비드 worker) 위에서 ELK 노드 배치 결정
- ECK Operator 로 ES 3-노드 hot/warm/cold tiering + ILM 라이프사이클
- Fluent Bit DaemonSet 의 inotify 한계, modify 필터 함정, JSON merge 파이프라인
- Next.js standalone 빌드와 비슷한 ECK secureSettings 의 빌드/런타임 분기 함정
- Kibana 외부 노출 (Cloudflare Tunnel + nginx 분기)
- R2 (S3 호환) 로 ES 스냅샷 백업 (daily SLM + 14d retention)
- 5분 윈도 ERROR 스파이크 → Telegram 알람 (Watcher/ElastAlert 없이 CronJob 으로)
- 전 과정 GitOps — helm-deploy 리포에 push 만 하면 ArgoCD 가 자동 동기화
1. 왜 또 ELK 인가 — Loki 와 OpenSearch 사이에서 ECK 를 고른 이유
홈랩에는 이미 kube-prometheus-stack 이 깔려있어 메트릭은 풍부합니다. 그런데 24 개 네임스페이스에 50 개 가까운 파드가 돌아가는데 로그를 보려면 매번 kubectl logs deploy/foo -n bar --tail=200 을 치고 있더군요. 검색·필터·시계열 어그리게이션은 사실상 불가능한 상태.
후보 3 가지를 두고 저울질했습니다.
| 후보 | 장점 | 단점 |
|---|---|---|
| Loki + Promtail | 가벼움, 라벨 인덱스만 저장, Grafana 그대로 활용 | 풀텍스트 검색 약함, 머신러닝 anomaly 부재 |
| OpenSearch | Apache 2.0, AWS 가 push 함 | Elastic 생태계 도구(Beats, ECK)와 일부 비호환 |
| ECK (Elastic Cloud on Kubernetes) | basic 라이센스 free 에도 RBAC/TLS/Kibana/Alerting 포함, Operator 가 자동화 | RAM 무거움, 라이센스 변경 리스크 |
결론은 ECK basic 으로 갔습니다. 포트폴리오 시연 용도에서 Kibana 의 Discover/Lens/Dashboard 가 주는 시각적 임팩트가 결정적이고, Watcher 같은 platinum 기능은 어차피 안 쓸 거라 basic 으로 충분합니다.
2. 노드 배치 — 메모리·디스크 가용량과 역할 라벨 매핑
5 노드 현재 가용량을 먼저 찍어봅니다.
$ kubectl get node -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.status.allocatable.cpu}{"\t"}{.status.allocatable.memory}{"\t"}{.status.allocatable.ephemeral-storage}{"\n"}{end}'
david 6 15.7GB 222GB (monitoring 노드, role=ai-monitoring)
ilwon 12 32GB 465GB (master+etcd, storage-tier=nvme)
lemuel 4 32GB 401GB (master+etcd, tier=management)
louise 8 16GB 475GB (worker, role=general)
solomon 4 15.7GB 699GB (master+etcd, tier=storage-backup)
kubectl top nodes 로 현재 사용량 빼면 전체 여유 메모리 ≈ 80GB+, CPU 70% 여유. 충분합니다.
ES 3-노드 hot/warm/cold tiering 으로 배치:
| 티어 | 노드 | 역할 | Heap | 디스크 | 이유 |
|---|---|---|---|---|---|
| hot | 일원 | master + ingest + data_hot | 4 GB | 200 GB NVMe | 가장 빠른 디스크 + 단일 마스터 |
| warm | 루이스 | data_warm + ingest | 3 GB | 300 GB | 워커 노드라 자유로움 |
| cold | 솔로몬 | data_cold | 2 GB | 500 GB | 디스크 가장 큰 노드, 백업용 라벨과도 일치 |
데이비드는 모니터링 노드(Prometheus warm) 라서 ES 노드는 제외하고 ECK Operator 만 배치. 르무엘은 control-plane 부담을 안 주기 위해 ES 노드 제외.
Kibana 1 대는 루이스에 같이 두고, Fluent Bit 은 DaemonSet 으로 5 노드 모두에.
3. 정적 PV — local-path 가 무작위 노드에 PVC 를 박는 함정 회피
K3s 의 기본 local-path-provisioner 는 PVC 가 어느 노드에서 처음 mount 되느냐에 따라 PV 가 그 노드에 생깁니다. ES 처럼 특정 노드에 디스크가 고정되어야 하는 워크로드에는 위험합니다. 한 번 죽고 다른 노드에서 재기동되면 데이터 분실 위험.
그래서 정적 PV 3 개를 노드 affinity 와 함께 미리 박았습니다.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata: { name: elk-hot }
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
reclaimPolicy: Retain
---
apiVersion: v1
kind: PersistentVolume
metadata: { name: elk-hot-ilwon-1, labels: { tier: hot, node: ilwon } }
spec:
capacity: { storage: 200Gi }
accessModes: [ReadWriteOnce]
persistentVolumeReclaimPolicy: Retain
storageClassName: elk-hot
local: { path: /var/local/es-hot }
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- { key: kubernetes.io/hostname, operator: In, values: [ilwon] }
이렇게 hot/warm/cold 3 개 SC + 3 개 PV. 노드에는 미리 /var/local/es-{hot,warm,cold} 디렉토리를 UID 1000 으로 만들어둡니다 (ES 컨테이너 user). 다행히 ilwon/louise/solomon 모두 첫 사용자 UID 가 1000 이라 mkdir -p && chown 1000:1000 한 번이면 끝.
4. ECK Operator + Elasticsearch CR — sync-wave 로 순서 보장
ArgoCD 의 root-app(App-of-Apps) 가 argocd-applications/elk/ 하위를 모두 자동 픽업합니다. 다만 CRD 가 먼저 설치되어야 ES CR 이 sync 됨, 그래서 argocd.argoproj.io/sync-wave 로 순서를 박았습니다.
00-storage.yaml (wave 0) — PV/SC
01-eck-operator.yaml (wave 1) — elastic.co/eck-operator 2.16.1, CRDs 자동 설치
02-elk-cluster.yaml (wave 2) — Elasticsearch CR (3 nodeSets) + Kibana CR
03-fluent-bit.yaml (wave 3) — fluent/fluent-bit 0.57.5 DaemonSet
Elasticsearch CR 핵심 부분:
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata: { name: logs, namespace: logging }
spec:
version: 8.16.1
nodeSets:
- name: hot
count: 1
config:
node.roles: [master, data_hot, data_content, ingest, remote_cluster_client]
node.attr.tier: hot
podTemplate:
spec:
nodeSelector: { kubernetes.io/hostname: ilwon }
initContainers:
- name: sysctl
securityContext: { privileged: true, runAsUser: 0 }
command: [sh, -c, "sysctl -w vm.max_map_count=262144"]
containers:
- name: elasticsearch
env: [{ name: ES_JAVA_OPTS, value: "-Xms4g -Xmx4g" }]
resources:
requests: { cpu: 500m, memory: 5Gi }
limits: { cpu: 2, memory: 6Gi }
volumeClaimTemplates:
- metadata: { name: elasticsearch-data }
spec:
accessModes: [ReadWriteOnce]
storageClassName: elk-hot
resources: { requests: { storage: 200Gi } }
# warm, cold 도 같은 구조로 nodeSelector + storageClass 만 바꿈
vm.max_map_count=262144 init container 는 ES 운영의 단골 함정. 안 하면 boostrap check 에서 죽습니다.
5. Fluent Bit — inotify 한도와 modify 필터 syntax 트랩
Fluent Bit DaemonSet 으로 /var/log/containers/*.log 를 수집해 ES 로 보냅니다. 첫 시도에 ilwon 노드에서 바로 깨졌습니다.
[error] [/src/fluent-bit/plugins/in_tail/tail_fs_inotify.c:365 errno=24]
Too many open files
[error] failed initialize input tail.0
ilwon 에 워크로드가 가장 몰려있어 컨테이너 로그 파일이 100+ 개. 기본 inotify 한도(128 instances, 65536 watches)를 다 먹어 init 실패. 5 노드 모두에서 한 번 풀어줍니다.
$ sudo sysctl -w fs.inotify.max_user_instances=1024 fs.inotify.max_user_watches=524288
$ cat > /etc/sysctl.d/99-inotify-elk.conf <<EOF
fs.inotify.max_user_instances=1024
fs.inotify.max_user_watches=524288
EOF
두 번째 함정은 modify 필터의 redact 패턴.
[FILTER]
Name modify
Match kube.*
Condition Key_value_matches password .+
Set password "***REDACTED***"
이게 init 시 [error] [filter:modify:modify.2] Unable to create regex(val) from ***REDACTED*** 로 죽습니다. Set value 가 regex 로 파싱되는 모양인데 docs 와 실제 동작이 어긋나서 redact 부분은 일단 빼고 lua 필터로 별도 분리하기로 했습니다. 운영에선 민감 필드 마스킹이 중요하니 후속 작업으로 ticket 만들어둡니다.
세 번째 함정 — customParsers 에 docker parser 를 중복 등록하면 parser named 'docker' already exists, skip 경고가 뜹니다. Helm chart 기본값에 이미 포함되어 있어 내 정의가 무시되는 거. 제거.
최종 파이프라인:
tail (/var/log/containers/*.log)
→ kubernetes filter (ns/pod/labels enrich + Merge_Log)
→ record_modifier (cluster_id=lemuel-onprem)
→ es output (https://logs-es-http:9200, Logstash_Format On, prefix logs-k8s)
ECK 가 자동 발급한 elastic 유저 비밀번호는 logs-es-elastic-user secret 의 elastic 키. 환경변수로 컨테이너에 주입:
env:
- name: ES_PASSWORD
valueFrom: { secretKeyRef: { name: logs-es-elastic-user, key: elastic } }
6. ILM 정책 — hot 7d → warm 30d → cold 90d → delete
데이터 스트림 + ILM 으로 자동 티어 마이그레이션. 24+ 네임스페이스에서 일일 5–15 GB 쌓일 텐데 cold tier 솔로몬 500 GB 면 90 일 보관 여유.
$ curl -X PUT https://localhost:9200/_ilm/policy/logs-k8s-policy -d '{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": { "max_age": "7d", "max_primary_shard_size": "30gb" },
"set_priority": { "priority": 100 }
}
},
"warm": {
"min_age": "7d",
"actions": {
"allocate": { "include": { "_tier_preference": "data_warm" }, "number_of_replicas": 0 },
"forcemerge": { "max_num_segments": 1 }
}
},
"cold": {
"min_age": "30d",
"actions": {
"allocate": { "include": { "_tier_preference": "data_cold" }, "number_of_replicas": 0 }
}
},
"delete": {
"min_age": "90d",
"actions": { "delete": {} }
}
}
}
}'
Index template logs-k8s 가 이 정책을 자동 적용 — 새 인덱스 만들어질 때마다 index.lifecycle.name=logs-k8s-policy 박힙니다.
7. Kibana 외부 노출 — Cloudflare Tunnel + nginx 분기
eln.lemuel.co.kr 도 그렇고 kibana.lemuel.co.kr 도 그렇고, 클러스터 노출은 다음 흐름.
Internet → Cloudflare Edge → cloudflared tunnel (on lemuel) → nginx:8092 (lemuel) → NodePort 30404 (cluster) → Kibana pod (louise)
ECK 가 만들어주는 logs-kb-http ClusterIP 서비스에 더해 NodePort 서비스 한 개를 직접 추가:
apiVersion: v1
kind: Service
metadata: { name: kibana-nodeport, namespace: logging }
spec:
type: NodePort
ports: [{ port: 5601, targetPort: 5601, nodePort: 30404 }]
selector:
common.k8s.elastic.co/type: kibana
kibana.k8s.elastic.co/name: logs
lemuel 호스트의 nginx 에는 8092 포트로 내부 server block 추가:
server {
listen 8092;
server_name kibana.lemuel.co.kr;
location / {
proxy_pass https://127.0.0.1:30404;
proxy_ssl_verify off;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-Proto https;
# ECK 가 self-signed TLS — verify off 필수
}
}
마지막으로 Cloudflare Zero Trust 대시보드의 lemuel-home 터널에 Public Hostname kibana.lemuel.co.kr → http://localhost:8092 추가하면 DNS 자동 생성 + 인증서까지 Cloudflare 가 알아서.
처음 진입했을 때 Discover 가 빈 화면이라 당황했는데, Data View 를 만들어줘야 합니다.
$ curl -X POST https://kibana.lemuel.co.kr/api/data_views/data_view \
-u elastic:$ES_PASS -H "kbn-xsrf: true" \
-d '{"data_view":{"title":"logs-k8s-*","name":"k8s-logs","timeFieldName":"@timestamp"}}'
이러면 Playwright 자동화로 검증해도 깔끔하게 48,025 hits 가 잡힙니다.
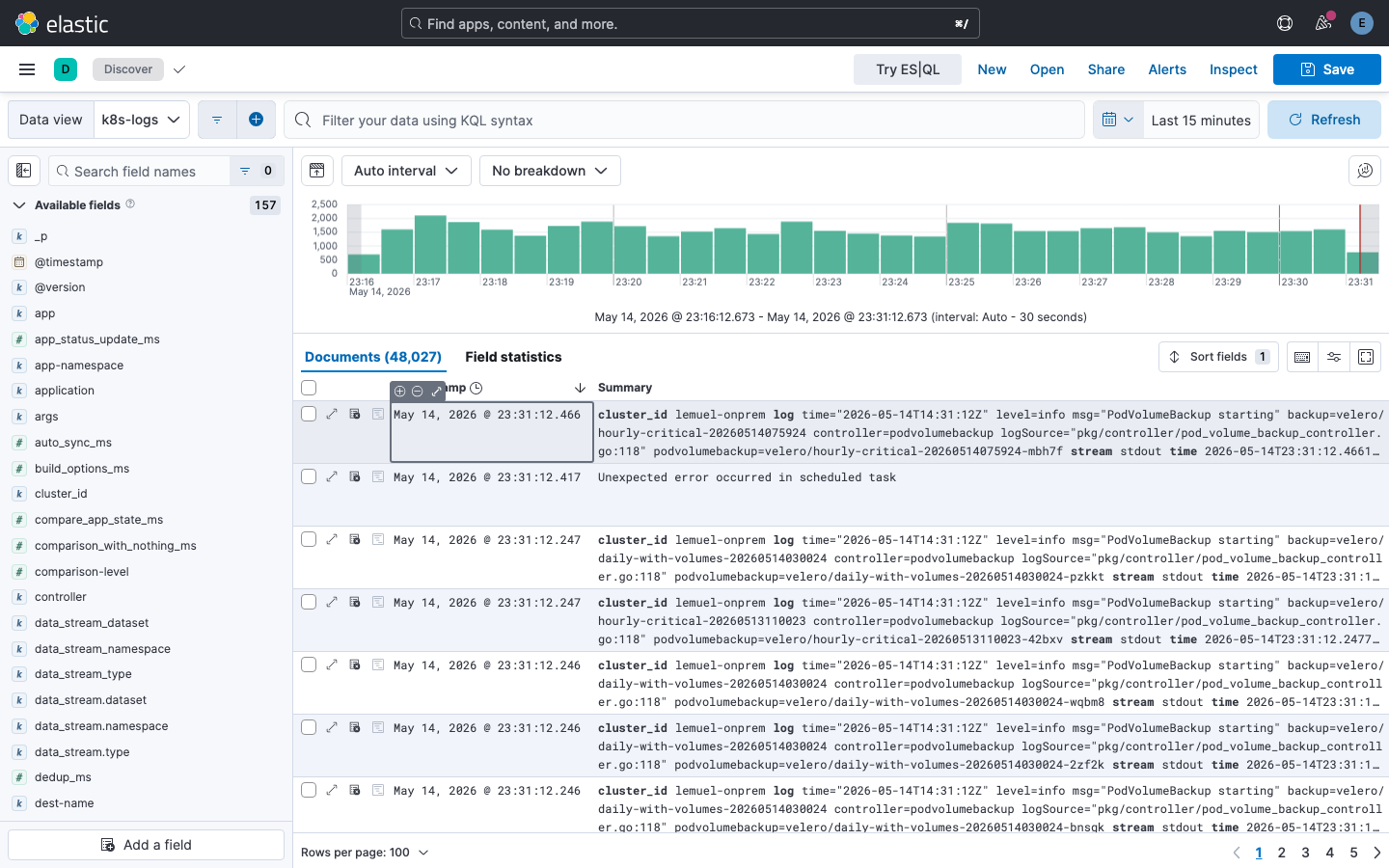
8. R2 스냅샷 백업 — secureSettings 의 빌드 vs 런타임 함정
ES 스냅샷은 S3 호환 저장소면 어디든 됩니다. 홈랩은 이미 Velero 가 Cloudflare R2 로 쿠버네티스 백업을 보내고 있어서 같은 버킷의 별도 prefix 를 재활용했습니다.
ECK 에서는 secureSettings 로 ES keystore 에 자격증명을 안전하게 주입합니다. K8s secret 이름만 지정하면 ECK 가 알아서 init container 로 keystore 에 박아줍니다.
spec:
secureSettings:
- secretName: es-r2-credentials
$ kubectl -n logging create secret generic es-r2-credentials \
--from-literal=s3.client.r2.access_key=... \
--from-literal=s3.client.r2.secret_key=...
여기서 한 번 더 함정. secret 을 만들고 spec 만 바꿔도 이미 떠있는 pod 의 keystore 에는 반영되지 않습니다. ECK 가 keystore 를 다시 박는 init container 는 pod 가 새로 뜰 때만 실행. kubectl delete pod logs-es-{hot,warm,cold}-0 으로 rolling restart 시켜야 keystore 에 s3.client.r2.* 가 추가됩니다.
$ kubectl -n logging exec logs-es-hot-0 -- /usr/share/elasticsearch/bin/elasticsearch-keystore list
keystore.seed
s3.client.r2.access_key
s3.client.r2.secret_key ← 이게 보이면 성공
이거 모르고 한참 Unknown s3 client name [r2] 에러로 시간을 깎았습니다. Next.js standalone 빌드의 next.config rewrites 가 빌드 시점에 destination 베이크되는 거랑 본질이 같은 트랩입니다 — “설정은 바꿨지만 실행 중인 프로세스는 모른다”.
이후 repository 등록과 SLM 정책 박는 건 단순합니다.
$ curl -X PUT https://localhost:9200/_snapshot/r2-elk-snapshots?verify=true -d '{
"type": "s3",
"settings": {
"client": "r2",
"bucket": "lemuel-backup",
"base_path": "elasticsearch/logs-cluster",
"endpoint": "...r2.cloudflarestorage.com",
"protocol": "https",
"path_style_access": true
}
}'
# {"acknowledged":true}
$ curl -X PUT https://localhost:9200/_slm/policy/daily-logs-snapshot -d '{
"schedule": "0 30 3 * * ?",
"name": "<daily-logs-{now/d}>",
"repository": "r2-elk-snapshots",
"config": { "indices": ["logs-k8s-*", ".ds-logs-k8s-*"] },
"retention": { "expire_after": "14d", "min_count": 3, "max_count": 14 }
}'
첫 스냅샷은 19.4 초만에 R2 로 업로드 완료. 매일 03:30 자동, 14 일 보관.
9. Telegram ERROR 알람 — Watcher/ElastAlert 없이 CronJob 으로
Watcher 는 platinum 라이센스, ElastAlert 는 별도 컨테이너 + 별도 설정 파일. 50 명 이하 홈랩 규모에서는 둘 다 오버스펙입니다. 그냥 5 분 주기 K8s CronJob 으로 끝냅니다.
apiVersion: batch/v1
kind: CronJob
metadata: { name: log-error-alerter, namespace: logging }
spec:
schedule: "*/5 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: alerter
image: curlimages/curl:8.10.1
command: [sh, -c, |
ES_PASS=$(cat /es/elastic)
QUERY='{
"size": 0,
"query": { "bool": { "filter": [
{ "range": { "@timestamp": { "gte": "now-5m" } } },
{ "bool": { "should": [
{ "term": { "level": "ERROR" } },
{ "term": { "level": "FATAL" } },
{ "match_phrase": { "message": "Exception" } },
{ "match_phrase": { "message": "Traceback" } }
] } }
] } },
"aggs": { "by_ns": { "terms": { "field": "kubernetes.namespace_name" } } }
}'
RESP=$(curl -sS -k -u "elastic:$ES_PASS" -X POST \
"https://logs-es-http.logging.svc:9200/logs-k8s-*/_search" -d "$QUERY")
# 임계치 초과 ns 만 awk 로 추출 → telegram 발송
...
]
처음에 log: "ERROR" 로 match_phrase 했다가 0 건만 나와서 한참 디버그. 알고 보니 Fluent Bit 의 kubernetes filter 가 Merge_Log On 으로 JSON 로그를 펼치면서 Spring Boot 의 level=ERROR 가 최상위 필드 로 올라옵니다. 그래서 term: { "level": "ERROR" } 가 정답.
검증을 위해 임계치 1 로 잠시 낮춰 강제 실행:
ALERT SENT
settlement-prod : 149건
settlement-staging : 148건
Telegram 알림 도착 확인 후 임계치를 운영값 20 으로 복원. 진짜 ERROR 스파이크 발생 시에만 알람이 옵니다.
10. 결과 — 24 ns 의 16,809 docs / 8.4 MB / 1 분 만에 인덱싱
$ kubectl -n logging exec logs-es-hot-0 -- curl -k -u elastic:$ES_PASS \
https://localhost:9200/_cat/indices/logs-k8s*?v
health status index docs.count store.size
yellow open .ds-logs-k8s-2026.05.14-2026.05.14-000001 16,809 8.4mb
네임스페이스별 분포 — 운영 트래픽이 그대로 보입니다.
13,351 velero (백업 워크로드, 정상)
1,840 argocd (sync log)
1,175 kafka (broker activity)
480 lowshopping-prod
437 sparta-prod
347 settlement-prod
...
11. 회고 — 4 시간이면 풀스택, 다만 시행착오 6 번
전체 작업 시간은 빌드+롤아웃 대기 포함 약 4 시간. 빌드는 ArgoCD Image Updater + helm-deploy 가 자동 처리하니 실제 손이 가는 시간은 30 % 정도.
손이 가는 시간을 잡아먹은 시행착오 모음:
fluent-bitchart 버전 0.49.2 — 존재하지 않음. 0.57.5 가 실제 최신.- modify 필터 Set syntax — docs 와 실제 동작 다름. redact 부분 일단 제거.
- ilwon inotify 한도 초과 — 5 노드 모두 sysctl 영구 적용.
- ECK secureSettings 는 pod restart 가 필요. 변경만으론 keystore 반영 안 됨.
- ERROR 검색 필드명 —
log가 아니라level과message. Merge_Log 결과 구조 이해 필요. - helm template YAML 파싱 — bash 다중 라인 문자열의 indent 깨짐.
printf한 줄로 해결.
각각 5 분에서 30 분씩 깎아먹었지만 모두 메모리에 남겨뒀습니다. 다음 프로젝트의 ELK 도입은 1 시간이면 끝낼 수 있을 것 같습니다.
12. 다음 작업 — Lens 대시보드 자동화 + 민감 필드 마스킹
지금은 Discover 와 Index Management 정도만 쓸 만한 상태. 다음으로는
- Kibana Lens 대시보드 자동 import (saved_objects API + Pulumi / kbn-bulk)
- 네임스페이스별 5xx 비율, 응답 시간 p95, ERROR 추이
- Fluent Bit Lua 필터로 password/Authorization/JWT 토큰 마스킹
- ES 노드 사이 cross-tier 데이터 이동 검증 (현재는 hot tier 만 사용 중)
- Velero 백업이 ES 자체 snapshot 과 겹치지 않도록 BackupSchedule 조정
GitOps 흐름에 다 녹였으니 PR 하나로 끝나는 작업들입니다.
부록 — 전체 helm-deploy 디렉토리 구조
helm-deploy/
├── argocd-applications/
│ └── elk/
│ ├── 00-storage.yaml # wave 0 — PV/SC
│ ├── 01-eck-operator.yaml # wave 1 — Elastic ECK Operator chart
│ ├── 02-elk-cluster.yaml # wave 2 — ES + Kibana CRs
│ └── 03-fluent-bit.yaml # wave 3 — Fluent Bit DaemonSet
└── charts/
├── elk-storage/ # 정적 PV + 3 StorageClass
└── elk-cluster/ # ES CR + Kibana CR + NodePort svc + alert CronJob
부트스트랩 1 회 (root-app.yaml apply) 이후 git push 만으로 전체 ELK 가 셀프 힐링되는 GitOps. 사람이 손대는 부분은 임계치 조정과 PR review 정도입니다.
TL;DR — ECK + Fluent Bit + R2 snapshot + Telegram alert 까지 풀스택 ELK 가 K3s 홈랩에서도 4 시간이면 가동된다. 시행착오 6 번을 기록으로 남겨 다음 프로젝트는 1 시간으로 단축한다.