K3s 홈랩 사용기 — *직접 만든 대시보드* 로 6 노드 를 지키는 법
집 에 6 대 의 머신 으로 K3s 클러스터 를 굴린 지 두 달 이 넘었다. 노트북 몇 대, 2014 년 산 맥 미니, 데스크탑 하나 — 제각각 인 하드웨어 위 에서 60 개 namespace / 338 개 pod 가 돈다. 이 글 은 그 홈랩 을 운영 하며 직접 만든 대시보드 이야기, 그리고 “Alerts 132” 인데 왜 멀쩡 한가 라는 홈랩 특유 의 현실 에 대한 사용기.
1. 왜 또 대시보드 를 만들었나
이미 Grafana(메트릭) 와 Kibana(로그) 가 있다. 그런데 도 별도 로 k3s.lemuel.co.kr 에 가벼운 대시보드 를 하나 더 만들었다. 이유:
- Grafana 는 메트릭 시계열 에 최적 — “지금 뭐 가 죽었나” 를 한 눈 에 보기 엔 무겁다
- Kibana 는 로그 — 역시 “클러스터 전체 건강” 요약 은 아니다
- 내가 매일 아침 궁금한 건 딱 네 줄:
- 노드 다 살아 있나?
- pod 몇 개 고, 문제 몇 개 냐?
- 지금 시끄러운 알림 이 뭐냐?
- 어느 namespace 가 아프냐?
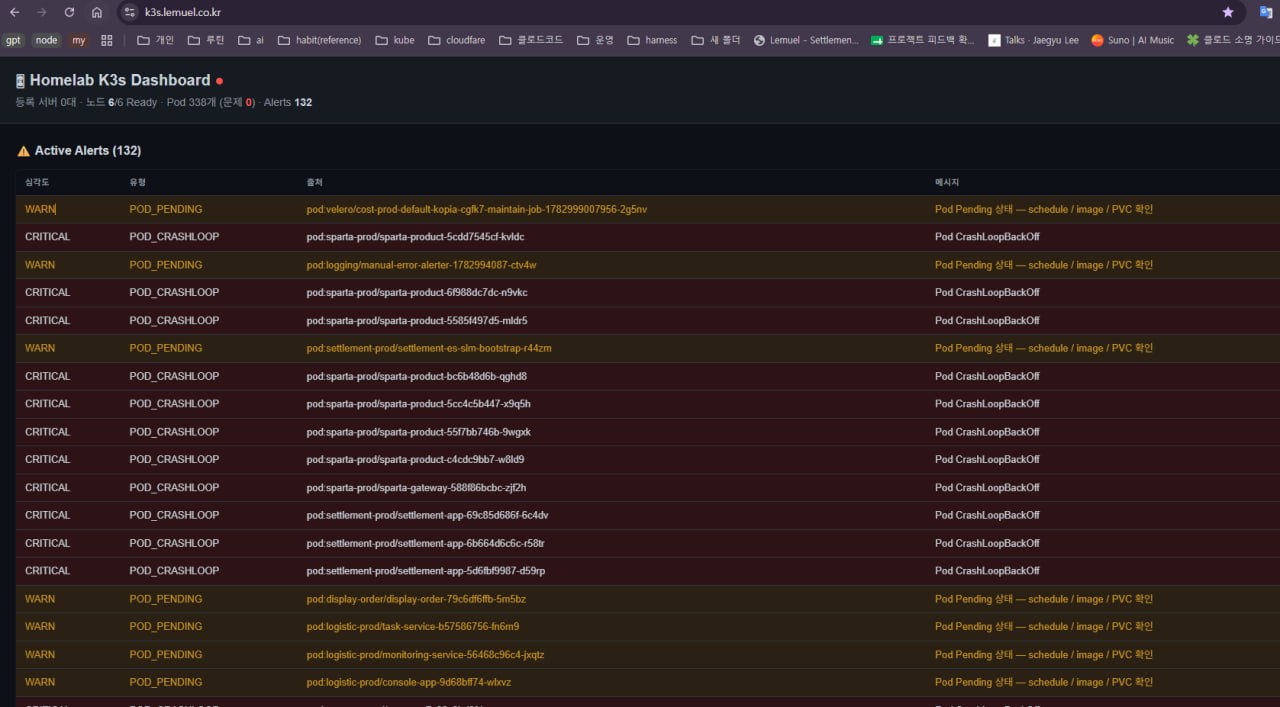
그래서 만든 게 위 화면. 상단 요약 한 줄 + Active Alerts 테이블. 군더더기 없이 “지금 상태” 만. 홈랩 은 내가 유일한 운영자 라, 남 보여줄 대시보드 가 아니라 내가 5 초 안 에 파악 할 화면 이 필요 했다.
2. 화면 읽기
상단 요약:
📟 Homelab K3s Dashboard ●
등록 서버 0 대 · 노드 6/6 Ready · Pod 338 개 (문제 0) · Alerts 132
- 노드 6/6 Ready — 6 대 전부 살아 있음 ✅
- Pod 338 개 (문제 0) — 실제 로 죽어 있는 pod 는 0 ✅
- Alerts 132 — 그런데 알림 은 132 개 ⚠️
여기서 딱 걸린다. “문제 0” 인데 “Alerts 132”? 이 모순 이 오늘 글 의 핵심 이다.
Active Alerts 테이블 을 보면:
| 심각도 | 유형 | 예시 출처 | 메시지 |
|---|---|---|---|
| WARN | POD_PENDING | velero/cost-prod-...-maintain-job |
Pod Pending — schedule/image/PVC 확인 |
| CRITICAL | POD_CRASHLOOP | sparta-prod/sparta-product-... |
CrashLoopBackOff |
| WARN | POD_PENDING | logging/manual-error-alerter-... |
Pod Pending |
3. “Alerts 132” 의 정체 — 신호 와 소음
글 을 쓰며 실제 클러스터 를 그 순간 에 직접 확인 해 봤다:
$ kubectl get pods -A --no-headers | grep -Ev 'Running|Completed' | wc -l
0
지금 이 순간 비정상 pod 는 0 개. 대시보드 상단 의 “문제 0” 이 맞다. 그럼 Alerts 132 는 뭐냐 — 뜯어 보면 홈랩 알림 의 전형적 인 구성 이다:
- 롤아웃 중 순간 CrashLoop —
sparta-prod는 조금 전 배포 가 돌았다. 새 pod 가 이미지 pull·초기화 하는 몇 초~몇 분 동안 CrashLoop/Pending 로 잡혔다가 스스로 회복. 알림 은 그 순간 을 포착 했지만 pod 는 이미 정상. - Job / CronJob 의 Pending —
velero/...-maintain-job같은 배치 작업 은 뜰 때 잠깐 Pending. 끝나면 Completed. 죽은 게 아니다. - 의도적 테스트 —
logging/manual-error-alerter는 이름 그대로 알림 파이프라인 이 잘 도는지 확인 하려고 일부러 에러 를 내는 pod. 알림 이 뜨는 게 정상.
즉 132 알림 의 대부분 은 “지금 고장” 이 아니라 “지나간 순간·자가회복·의도된 테스트” 다. 홈랩 은 노드 성능 이 들쭉날쭉 하고 배포 도 잦아서 이런 순간 알림 이 원래 많다.
교훈: 알림 개수 그 자체 는 지표 가 아니다. “지금 실제 로 죽어 있나” 가 지표 다. 이걸 헷갈리면 132 개 알림 에 파묻혀 진짜 하나 를 놓친다.
4. 홈랩 K3s 를 두 달 굴려 보고 얻은 것
① 하드웨어 는 못 나도 클러스터 는 된다. 노트북·10 년 된 맥 미니 를 섞어 도 K3s 는 돈다. 대신 성능 편차 를 인정 해야 한다. CPU 약한 노드 는 아예 cordon 으로 스케줄 을 뺐다.
② 진짜 적 은 “고장” 이 아니라 “노이즈”. 노드 는 잘 안 죽는다. 정작 시간 을 잡아먹는 건 재부팅 후 방화벽 이 오버레이 네트워크 를 막거나, 배포 경합 으로 알림 이 쏟아지는 것 같은 운영 잡음. 그래서 “지금 실제 상태” 를 5 초 에 보는 대시보드 가 값 을 한다.
③ 관측 은 3 층 이 필요 하다.
- 메트릭 → Grafana (추세·리소스)
- 로그 → Kibana (무슨 일 이 있었나)
- 상태 요약 → 이 커스텀 대시보드 (지금 괜찮나)
셋 이 겹치는 것 같지만 묻는 질문 이 다르다. 하나 로 다 하려다 오히려 아무 것 도 빨리 못 본다.
④ 내 도구 를 만들 수 있다는 것. “노드 몇, pod 몇, 알림 뭐” 를 보여주는 화면 은 별 거 아닌 것 같아도 매일 아침 의 30 초 를 아껴 준다. 남 이 만든 대시보드 에 나 를 맞추는 대신, 내 질문 에 맞춘 화면 을 만드는 것 — 홈랩 의 진짜 재미 는 거기 있다.
5. 한 줄 정리
노드 6/6, Pod 338, Alerts 132, 실제 문제 0.
이 네 숫자 가 홈랩 K3s 운영 의 현실 을 압축 한다 — 대부분 은 잘 돌고, 알림 은 시끄럽고, 진짜 문제 는 드물다. 그 사이 에서 “지금 정말 괜찮은가” 를 5 초 에 답 하는 화면 하나. 그게 두 달 운영 의 결론 이다.
다음 은 이 대시보드 의 알림 을 어떻게 걸었는지(Pending/CrashLoop 판정 로직) 편 으로.