Grafana 실전 사용 가이드 — K3s 클러스터 를 *한 눈 에* 보는 법
내 6 노드 K3s 클러스터 는 60 개 namespace / 339 개 pod 가 돈다. 이걸 kubectl get pods 로 일일이 확인 하는 건 불가능. Prometheus 가 metric 을 긁고, Grafana 가 그걸 그림 으로 보여 준다. 이 글 은 kube-prometheus-stack 이 깔아 주는 기본 대시보드 를 어떻게 읽고 쓰는지 — 실 스크린샷 과 함께 정리.
1. Grafana 가 무엇 을 해결 하는가
모니터링 없는 운영:
$ kubectl top nodes # 지금 이 순간 만
$ kubectl top pods -A
$ kubectl logs deploy/app # 텍스트 스크롤
문제:
- 지금 만 보임 — 1 시간 전 CPU 스파이크 는 못 봄
- 노드 별 / namespace 별 추세 를 한 눈 에 못 봄
- “어제 밤 에 왜 느렸지?” 에 답 못 함
관측 스택 의 답:
- Prometheus = 시계열 DB. 각 노드 의
node_exporter, 각 pod 의 metric 을 15 초 마다 스크랩 해서 저장 - Grafana = 그 데이터 를 쿼리(PromQL) 해서 그래프 로. 시간 축 을 과거 로 되돌려 볼 수 있음
- Alertmanager = 임계치 넘으면 알림
즉 Grafana 는 데이터 를 만들 지 않는다. Prometheus 가 쌓은 걸 보여 줄 뿐. 이 분리 를 이해 하면 절반 은 끝.
2. 로그인 + 첫 화면
URL: https://grafana.lemuel.co.kr (또는 자신 의 도메인)
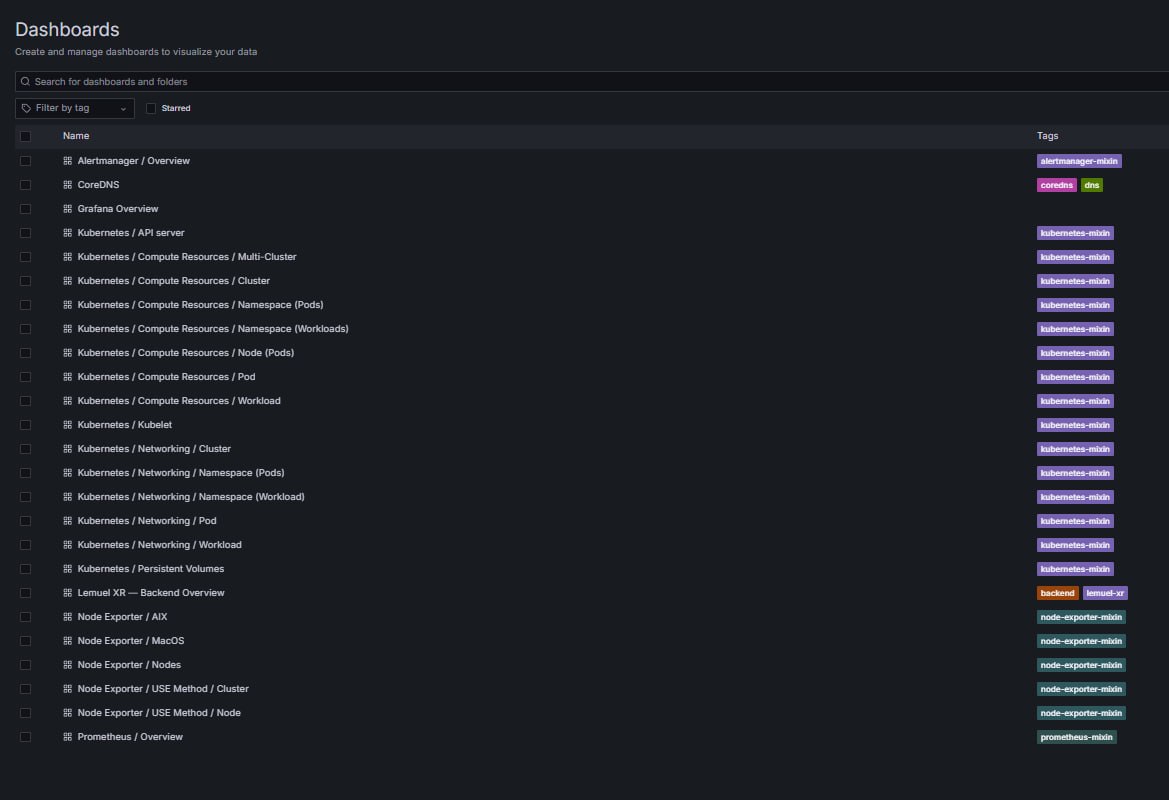
kube-prometheus-stack 을 Helm 으로 깔면 Grafana 가 같이 배포 되고, Prometheus 가 자동 으로 datasource 로 연결 돼 있다. 로그인 하면 별 설정 없이 바로 대시보드 가 채워져 있다 — 위 스크린샷 이 그 Dashboards 목록.
3. 기본 대시보드 목록 읽는 법
스크린샷 의 Tags 색깔 을 보면 출처 가 보인다:
| 태그 | 무엇 | 언제 봄 |
|---|---|---|
kubernetes-mixin |
K8s 표준 대시보드 세트 (API server / Compute / Networking / Kubelet …) | 클러스터·워크로드 상태 |
node-exporter-mixin |
노드(호스트) 레벨 — CPU/메모리/디스크/네트워크 | 하드웨어·OS 자원 |
prometheus-mixin |
Prometheus 자체 상태 | 스크랩 이 잘 되나 |
alertmanager-mixin |
알림 규칙·발송 상태 | 알림 파이프라인 |
coredns |
클러스터 DNS | 이름 해석 지연 의심 시 |
mixin = 커뮤니티 가 관리 하는 대시보드 + 알림 규칙 템플릿 묶음.
kube-prometheus-stack이 이걸 통째 로 넣어 준다. 그래서 깔자 마자 20 여 개 대시보드 가 생기는 것.
맨 아래 Lemuel XR — Backend Overview (backend, lemuel-xr 태그) 는 내 가 직접 만든 커스텀 — 이건 6 절 에서.
4. 실전 — 자주 여는 대시보드 3 개
① Kubernetes / Compute Resources / Cluster
클러스터 전체 의 CPU/메모리 를 namespace 단위 로 쌓아 보여 준다.
- “클러스터 가 지금 얼마나 차 있나” 를 한 화면 에.
- 상단 요약: CPU Utilisation / Requests / Limits, Memory 동일. Requests 합 이 노드 용량 을 넘으면 새 pod 가
Pending뜨는 원인.
② Node Exporter / Nodes
노드 하나 를 골라(상단 드롭다운) 그 호스트 의 CPU·메모리·디스크 I/O·네트워크 를 본다.
- “특정 노드 만 느리다” 싶을 때. 무선 노드 의 네트워크 재전송, 빌드 노드 의 디스크 포화 같은 게 여기 서 잡힌다.
③ Kubernetes / Compute Resources / Namespace (Pods)
namespace 하나 안 의 pod 별 자원 사용.
- “이 앱 이 메모리 를 얼마나 먹나 / OOM 직전 인가” 확인.
limits대비 실제 사용 곡선 이 붙어 있으면 위험 신호.
5. 패널 조작 — 이것만 알면 됨
- Time range (우 상단):
Last 6 hours→Last 7 days로 늘려 추세 를 본다. 어제 밤 스파이크 는 여기 서 되돌려 확인. - Variables (좌 상단 드롭다운):
datasource / cluster / namespace / node를 바꾸면 같은 대시보드 로 다른 대상 을 본다. 대시보드 를 새로 만들 필요 없음. - 패널 → Edit: 그래프 제목 클릭 →
Edit→ 그 패널 의 PromQL 쿼리 가 그대로 보인다. 여기서 PromQL 을 배우는 게 가장 빠름. - Explore (좌 메뉴 나침반): 대시보드 없이 PromQL 을 즉석 으로 날려 보는 곳. 예:
# namespace 별 메모리 사용 상위 sort_desc(sum(container_memory_working_set_bytes) by (namespace))
6. 커스텀 대시보드 만들기
기본 대시보드 로 부족 하면 직접 만든다. 나 의 Lemuel XR — Backend Overview 가 그 예시.
방법 A — 패널 조립: New → New dashboard → Add visualization → datasource(Prometheus) 선택 → PromQL 입력 → 시각화 타입 고르고 저장.
방법 B — JSON import (추천): 이미 잘 만든 대시보드 는 번호 로 가져온다.
Dashboards → New → Import→ grafana.com/dashboards 의 dashboard ID 입력.- 예:
1860(Node Exporter Full),315(K8s cluster monitoring).
팁: 커스텀 대시보드 도 JSON 으로 export 해서 git 에 커밋 해 두면, 클러스터 를 갈아 엎어도 그대로 복원 된다. GitOps 의 대상 은 앱 뿐 아니라 대시보드 도 포함.
7. 정리 — 3 단 관측 흐름
node_exporter / pod metric → Prometheus(수집·저장) → Grafana(시각화)
│
└→ Alertmanager(임계치 알림)
- 깔면 바로 20+ 대시보드 — kube-prometheus-stack 덕분. 처음 부터 만들 필요 없다.
- 읽는 순서: 클러스터 전체(①) → 이상한 노드(②) → 문제 namespace/pod(③) 로 좁혀 들어간다.
- PromQL 은 패널 Edit / Explore 에서 실물 을 보며 익히는 게 제일 빠르다.
- 커스텀 대시보드 는 JSON 으로 git 에 — 앱 처럼 버전 관리.
배포 는 ArgoCD(→ ArgoCD 실전 사용 가이드) 로, 관측 은 Grafana 로. 이 둘 이 있으면 클러스터 를 눈 감고 도 운영 할 수 있다.