ELK 로그 스택 실전 — Kibana 로 K3s 클러스터 로그 를 *다* 보는 법
앞 글 에서 Grafana 는 메트릭(Prometheus) 을 본다 고 했다. 그럼 로그 는? 로그 는 ELK 스택 — Elasticsearch + Logstash + Kibana — 가 맡는다. 내 6 노드 K3s 클러스터 에서 지금 이 순간 에도 초당 수십 건 의 로그 가 쌓이고 있고, 인덱스 에는 약 1,500 만 건 이 들어 있다. 이 글 은 그 로그 가 어디 를 거쳐 Kibana 까지 오는지, 그리고 실 스크린샷 으로 무엇 을 읽는지 를 정리.
1. 각 도구 가 무엇 을 하는가
가장 헷갈리는 지점 이 ES / Logstash / Kibana 의 역할 구분 이다. 한 줄 씩:
- Elasticsearch = 로그 를 저장 하고 검색 하는 엔진. DB + 검색엔진. 화면 은 없다. API(
:9200) 만 있다. - Logstash = 로그 가 지나가며 형태 를 다듬는 가공 파이프라인. 저장 하지 않는다 — 흘려 보낸다.
- Kibana = ES 안 의 데이터 를 사람 이 보는 웹 UI. 대시보드 / 검색 / 그래프.
비유 하면:
| 도구 | 역할 | 비유 |
|---|---|---|
| Elasticsearch | 저장·검색 | 창고 (물건 이 다 들어 있음) |
| Logstash | 가공 | 컨베이어 벨트 (지나 가며 다듬음) |
| Kibana | 조회 | 창고 를 보는 모니터 화면 |
즉 Kibana 는 ES 를 들여다 보는 창 이다. Grafana 가 Prometheus 를 안 만들 듯, Kibana 도 데이터 를 만들 지 않는다. 이 분리 를 잡으면 절반 은 끝.
2. 로그 는 어디 를 거쳐 오는가
로그 한 줄 이 pod 에서 Kibana 화면 까지 오는 경로:
모든 pod 의 stdout/stderr
→ fluent-bit (각 노드 에서 전량 수집, DaemonSet 5 노드)
→ Logstash (파싱·필드 추출·필터)
→ Elasticsearch(전량 저장, hot/warm/cold tier)
→ Kibana (조회 + 필터 + 대시보드)
핵심 은 fluent-bit 이 모든 pod 의 stdout/stderr 를 통째 로 긁는다 는 점. info 든 debug 든 정상 요청 로그 든 전부. Logstash 는 그걸 걸러내는 게 아니라 형태 만 다듬어서 ES 에 넣는다.
흔한 오해: “Kibana 는 문제 있는 로그 만 보여 준다.” → 아니다. 전부 올라오고, 그 중 error 만 보고 싶으면 필터 를 걸어서 골라 본다. 구조 가 반대다.
이게 왜 중요 하냐면 — 에러 가 안 났어도 그 직전 의 정상 로그 를 되짚어야 원인 을 찾는다. “문제 만 저장” 하면 그 맥락 이 통째 로 사라진다.
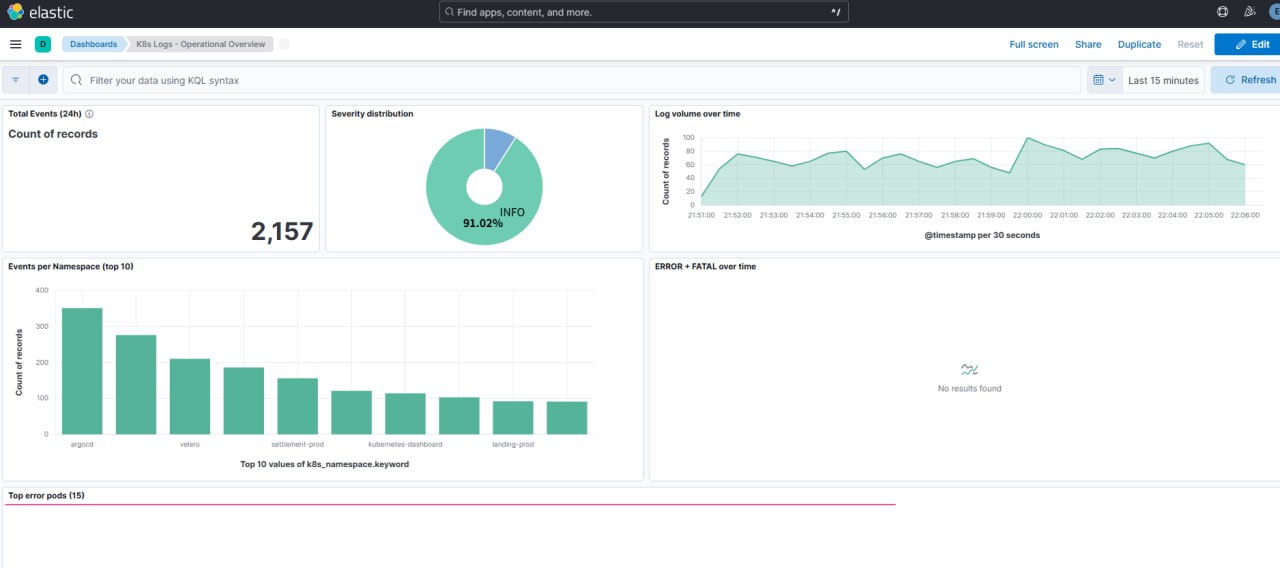
3. 첫 화면 — Operational Overview 대시보드
맨 위 스크린샷 이 그 증거 다. K8s Logs - Operational Overview 대시보드 를 Last 15 minutes 로 본 화면:
- Total Events:
2,157건 (최근 15 분치. 24 시간 이면 수백만) - Severity distribution: INFO 91.02% — 올라오는 로그 의 90% 넘게 가 정상 로그 다. 에러 가 아니다.
- ERROR + FATAL over time:
No results found— 지금 이 순간 에러 0 건 - Log volume over time: 30 초 당 60~90 건 이 꾸준히 들어옴 (정상 로그 가 계속 흐른다는 뜻)
- Events per Namespace (top 10):
argocd>velero>settlement-prod>kubernetes-dashboard>landing-prod…
이 한 장 이 앞 절 의 주장 을 그대로 증명 한다. “전부 저장 되고, 그 중 문제(error) 는 따로 집계” 하는 구조. INFO 91%, ERROR 0 건 — 건강 한 클러스터 의 전형 이다.
대시보드 는 전체 현황 요약판 이다. 로그 한 줄 한 줄 은 다음 절 의 Discover 에서 본다.
4. Discover — 로그 한 줄 씩 파고 들기
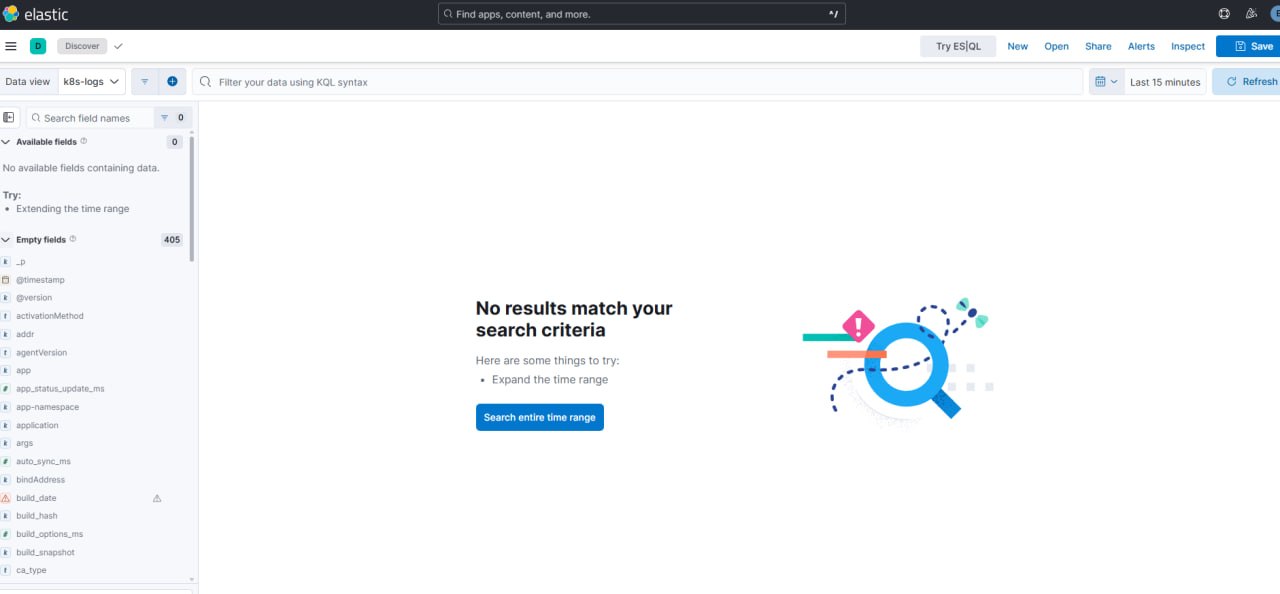
왼쪽 메뉴 의 Discover 는 raw 로그 를 검색 하는 화면 이다.
읽는 순서:
- Data view (좌상단
k8s-logs) — 어떤 인덱스 를 볼지 고르는 것. 데이터 가 안 보이면 여기 부터 확인. - 시간 범위 (우상단
Last 15 minutes) — Kibana 에서 가장 자주 실수 하는 곳. 로그 가 15 분 전 것 이면 아무 것 도 안 나온다. - KQL 검색창 —
k8s_namespace: "settlement-prod" and log.level: "error"처럼 필터. 이게 에러 만 골라 보는 방법. - 좌측 필드 목록 —
@timestamp,app,k8s_namespace… 클릭 하면 값 분포 를 바로 집계.
위 스크린샷 은
No results match your search criteria가 떠 있다. 고장 이 아니다. Last 15 minutes 범위 에 이 데이터뷰 조건 에 맞는 로그 가 마침 없었을 뿐. 파란 Search entire time range 버튼 을 누르거나 시간 을 넓히면 나온다. (Empty fields 가 405 개 로 잡혀 있는 것 도 같은 이유 — 그 시간창 에 값 이 안 들어온 필드 다.)
Kibana 첫 인상 의 90% 는 “왜 안 나오지?” 인데, 대부분 시간 범위 아니면 data view 문제 다. 이 둘 만 의심 하면 된다.
5. 내 클러스터 의 실제 구성
logging 네임스페이스 에 ECK operator 로 올린 스택:
Elasticsearch "logs" 8.16.1 — 3 노드 tier 구성 (ILM)
├─ logs-es-hot-0 (ilwon) 최신·자주 쓰는 로그
├─ logs-es-warm-0 (ilwon) 조금 지난 로그
└─ logs-es-cold-0 (solomon) 오래 된 로그 (저비용 보관)
Kibana "logs" 8.16.1 — green, 1 노드 (louise)
Logstash (logs-ls) — 1 노드
fluent-bit — DaemonSet 5 노드 (전 노드 로그 수집)
ILM(Index Lifecycle Management) 이 로그 를 hot → warm → cold → delete 로 자동 이동 시킨다. 새 로그 는 빠른 hot 노드 에, 오래 된 건 cold 로 밀어 디스크 를 아낀다. 정책 phase 가 100 개 넘게 정의돼 있다.
ES 가 왜 yellow 인가
kubectl get elasticsearch -n logging 을 치면 health 가 yellow 로 뜬다. 정상 이다. unassigned 샤드 가 있는데 전부 replica 다 — tier 당 노드 를 1 개 씩 만 돌려서 복제본 을 둘 자리 가 없어 배치 안 된 것 뿐. primary 샤드 는 전부 정상, 데이터 유실 은 없다. (다만 tier 노드 가 죽으면 복구 전 까지 그 tier 는 red 가 된다 — 홈 클러스터 의 HW 트레이드오프.)
6. Kibana 접속 — Ingress 가 없다
Grafana(grafana.lemuel.co.kr) 와 달리 Kibana 는 외부 도메인 이 없다. ClusterIP 서비스(logs-kb-http:5601) 만 있어서 포트포워드 로 붙는다:
kubectl -n logging port-forward svc/logs-kb-http 5601:5601
# → https://localhost:5601
# 로그인: elastic / <logs-es-elastic-user 시크릿 의 elastic 키>
비번 은 시크릿 에서 꺼낸다:
kubectl -n logging get secret logs-es-elastic-user \
-o jsonpath='{.data.elastic}' | base64 -d
외부 로 열려 있지 않은 건 의도 다 — 로그 에는 민감 정보 가 섞이기 쉬워서, 굳이 public ingress 를 안 붙였다.
7. 한 장 요약
- ES = 저장·검색 / Logstash = 가공 / Kibana = 조회. Kibana 는 ES 를 보는 창 일 뿐.
- 흐름:
pod 로그 → fluent-bit(전량) → Logstash(가공) → ES(전량 저장) → Kibana(조회+필터) - 문제 만 저장 하는 게 아니다. 전부 저장 하고 (INFO 91%), 필터 로 error 를 골라 본다.
- 대시보드 = 전체 요약, Discover = 로그 한 줄 씩. Discover 가 비면 시간 범위 / data view 부터 의심.
- health yellow 는 정상 — replica 를 둘 노드 가 없을 뿐, primary 는 멀쩡.
Grafana 로 메트릭 을, Kibana 로 로그 를 — 이 둘 이 관측(observability) 의 양 축 이다. 다음 은 둘 을 엮어 알림(Alerting) 까지 가는 편 으로.