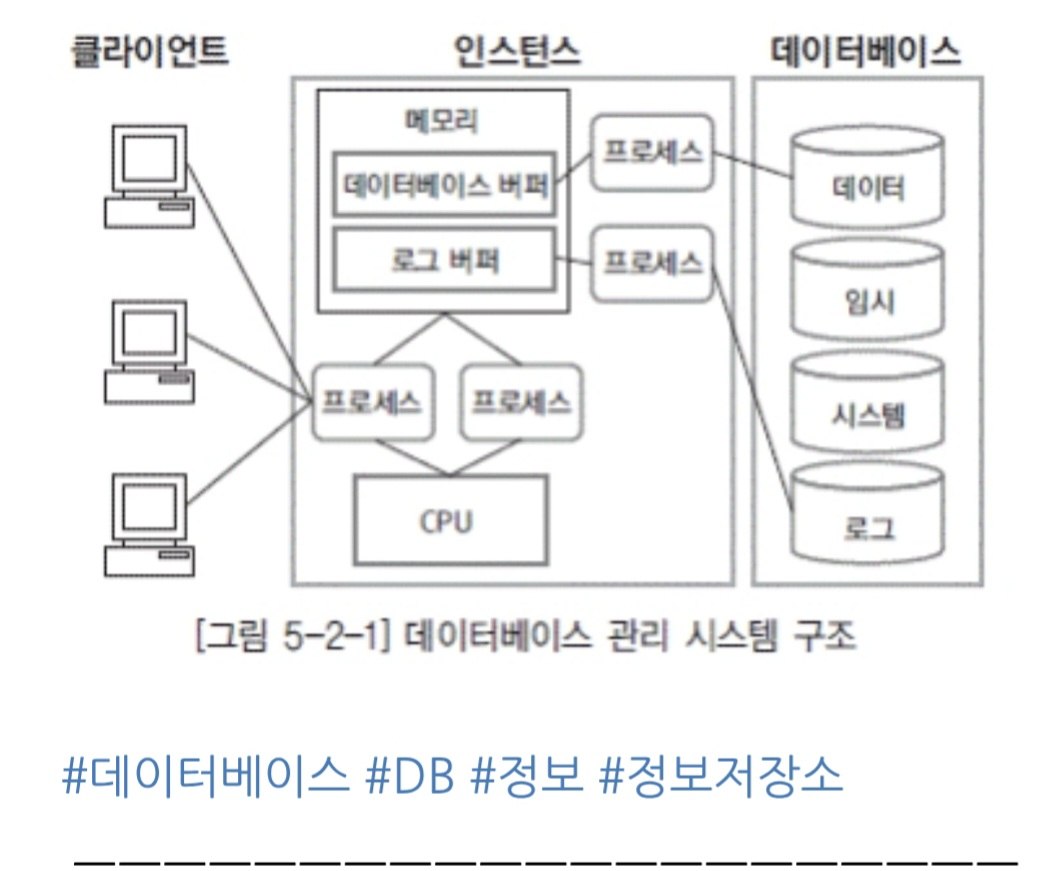
*데이터베이스 관리 시스템* 의 *3 층 구조* — *클라이언트 / 인스턴스 / 데이터베이스* 가 *왜 *그렇게 분리* 되는가
SELECT * FROM orders WHERE id = 1; — 단 한 줄 의 SQL. 0.5 ms 뒤 결과 가 내 IDE 의 *테이블 그리드 에 나타난다.
그 0.5 ms 안 에 내 노트북 의 *클라이언트 프로세스 가 TCP 패킷 으로 DB 서버 의 인스턴스 와 대화 하고, 인스턴스 의 *프로세스 가 메모리 의 *버퍼 를 뒤지고, 없으면 *디스크 의 *데이터 파일 에서 블록 을 끌어 오고, 동시에 *로그 파일 에 흔적 을 남기고, 내가 *읽은 그 한 줄 이 시스템 테이블 에서 권한 검증 까지 끝난 결과 다.
이 *3 층 의 분리 — 클라이언트, 인스턴스, 데이터베이스 — 가 현대 DBMS 의 *근본 골격. 왜 그렇게 *나뉘었는지, 각 층 이 *무엇 을 하는지, 9 년차 백엔드 개발자 가 *왜 이 구조 를 알아야 하는지 — 그 밀도 있는 해부.
이 글은 위 도식 (그림 5-2-1) 을 골격 으로 각 박스 의 *내부 메커니즘 + PostgreSQL / MySQL / Oracle 의 *동일 패턴 의 변주 + 실무 적 *함의 까지 밀도 있게 정리한다.
함께 보면 좋은 자매편 :
- MySQL 의 *7 가지 안정성 기둥* — 운영 적 시야
- Spring Boot HikariCP — *DB 연결 풀 의 깊이* — 클라이언트 측 의 *대표 적 도구
- 2 글 — *PAT 사고 회고 + DB 본질 (B+Tree / MVCC / Replication)* — 깊이 의 보충
TL;DR — 한 줄 결론
DBMS 는 클라이언트 가 *디스크 에 *직접 못 가게 막고, 그 사이 에 *인스턴스 라는 *살아 있는 프로세스 + 메모리 영역 을 세워 *모든 접근 의 *수문장 으로 둔다. *인스턴스 의 *메모리 (DB 버퍼 + 로그 버퍼) 가 디스크 의 *느림 을 *덮고, 프로세스 가 SQL 을 *기계 어로 번역 하며, 데이터베이스 의 *4 가지 파일 (데이터 / 임시 / 시스템 / 로그) 이 각자 의 책임 으로 분리 되어 있다. 이 *3 층 의 *얇은 분리 가 동시성 / 내구성 / 성능 / 보안 의 *4 가지 어려운 문제 를 *동시에 해결. 백엔드 개발자 가 *9 년 의 *어떤 시점 에든 *이 구조 의 어디 와 *어떻게 *말하고 있는지 를 알아야 한다.
1. 왜 *3 층 의 분리 가 필연 인가**
도식 의 클라이언트 - 인스턴스 - 데이터베이스 의 3 영역 — 처음 보면 *과도해 보임. 그냥 *파일 에 *직접 쓰면 되지 않나?*
1.1 *대안 — *클라이언트 가 *파일 을 직접 만지는 *세계**
수십 명 의 사용자 가 *각자 의 노트북 에서 같은 데이터 파일 을 직접 read/write. 결과 :
- 동시 쓰기 의 *훼손 — 두 명 이 *같은 행 을 동시에 수정 하면 어느 쪽 의 변경 이 남는지 비결정 적.
- 부분 쓰기 의 *유령 — 디스크 쓰기 가 *블록 단위. 전원 끊김 시 반쪽 쓰여진 상태 가 영원히 남음.
- 권한 의 *부재 — 모든 사용자 가 *모든 행 을 *모두 보임.
- 인덱스 의 *불일치 — 각자 *별도 캐시 로 인덱스 가 *서로 다른 진실 가짐.
- 쿼리 의 *재 발명 — 각 클라이언트 가 *조인 / 정렬 / 집계 의 알고리즘 을 *직접 구현.
이 5 가지 의 *재앙 의 동시 해결 자 가 *DBMS 인스턴스.
1.2 *인스턴스 — *수문장 + 두뇌 + 캐시 의 *합본**
도식 의 *가운데 박스 — 모든 *클라이언트 의 *요청 을 *받고, 모든 *디스크 접근 을 *통제 한다.
- 동시성 의 *조정 — 락 / MVCC / 트랜잭션 격리 수준 의 중앙 처리.
- 내구성 의 *보장 — WAL (Write-Ahead Log) 로 부분 쓰기 의 *유령 차단*.
- 권한 의 *집중 — 시스템 테이블 의 *RBAC / GRANT 가 모든 요청 의 *전제 조건.
- 인덱스 의 *유일 진실 — 공유 메모리 의 *B+Tree 가 *모든 클라이언트 의 *공동 자산.
- 쿼리 의 *최적화 의 *공유 — Optimizer 가 *수십 년 의 *집단 지능 의 *서비스 화.
결론 — 클라이언트 와 *데이터베이스 의 *분리 는 과도해 보이지만 *모든 어려운 문제 의 *해결 의 *전제 조건. 9 년 의 *프로덕션 의 *모든 안정성 이 *이 분리 에 기인.
2. 클라이언트 의 *실제 모습 — *내가 *항상 만지는 *그 곳**
도식 의 왼쪽 의 *3 개 PC — 현대 의 *맥락 에서 :
- 내 *IntelliJ / DBeaver / psql — 대화 형 클라이언트.
- 내 *Spring Boot 앱 / Node.js 서비스 / Python 스크립트 — 애플리케이션 클라이언트.
- 내 *batch job / Airflow worker / ETL 파이프라인 — 자동 화 된 클라이언트.
공통 점 — 모두 *DBMS 의 *프로토콜 (PostgreSQL frontend protocol, MySQL protocol, Oracle SQLNet)* 으로 TCP 연결 을 맺고 SQL 텍스트 를 주고 받음.
2.1 *클라이언트 측 의 *3 가지 핵심 도구**
1. 드라이버 — 프로토콜 의 *번역기
- JDBC (Java), psycopg (Python), npgsql (.NET), pq (Go) — 언어 마다 *DBMS 프로토콜 을 *언어 표현 으로 *번역.
- Spring 의 *JdbcTemplate / JPA 의 *Hibernate 는 그 위 의 *추상화.
2. 연결 풀 — TCP 핸드셰이크 의 *비용 회피
- DB 연결 1 개 의 *기동 비용 — TCP 3-way + TLS 핸드셰이크 + 인증 + 세션 초기화 = 수십 ~ 수백 ms.
- 연결 풀 (HikariCP) 이 재 사용 가능 한 연결 N 개를 *상시 유지. 애플리케이션 의 *수만 RPS 의 *모든 요청 이 그 풀 의 *N 개 *진짜 연결 을 *공유.
- 내 HikariCP 깊이 글 — 클라이언트 측 의 *가장 중요 한 *시스템 컴포넌트.
3. 세션 — *서버 측 의 *내 상태**
- 각 연결 이 *서버 의 *프로세스 (또는 *스레드) 한 개* 와 짝 을 이룸.
- 그 프로세스 가 *내 트랜잭션 / 임시 테이블 / SET 변경 / role 을 세션 의 *기억 으로 *유지.
- 연결 끊김 = *세션 종료 = *서버 측 자원 반납.
9 년 의 진실 — *DBMS 의 *대부분 의 *튜닝 의 *시작 점 이 *클라이언트 와 *서버 의 *경계 (연결 풀, 타임 아웃, 세션 의 일관성). 이 경계 를 *모르면 *수년 의 *디버깅 의 *지옥.
3. 인스턴스 의 *해부 — *도식 의 *심장**
도식 의 가운데 박스 가 DBMS 의 *진짜 본체. 처음 *시작 시점 부터 마지막 *셧다운 까지 살아 있는 *프로세스 + 메모리 의 합본.
3.1 *메모리 — *디스크 의 *느림 의 *덮개**
도식 의 메모리 안 에 2 가지 버퍼.
Database Buffer (Buffer Pool / Shared Buffers / Buffer Cache)
- 디스크 의 *데이터 페이지 를 최근 접근 한 것 부터 *RAM 의 *공유 메모리 에 캐시.
- 모든 클라이언트 가 *같은 버퍼 를 공유. 한 명 이 *읽은 행 을 *다른 명 이 *즉시 *디스크 안 보고 *읽음.
- 교체 알고리즘 — LRU (Least Recently Used) 의 변형. Hot page 는 *오래 머무름.
- 크기 의 *결정 적 중요성 — Buffer hit ratio (캐시 히트 율) 가 *95 % 이상 이 건강 한 DB. 80 % 미만 이면 *디스크 I/O 폭발.
| DBMS | 이름 | 기본 크기 | 권 장 |
|---|---|---|---|
| PostgreSQL | shared_buffers |
128 MB | RAM 의 25 % |
| MySQL (InnoDB) | innodb_buffer_pool_size |
128 MB | RAM 의 70 ~ 80 % (DB 전용 서버 시) |
| Oracle | SGA_TARGET |
광범위 | RAM 의 60 ~ 80 % |
Log Buffer (WAL Buffer / Redo Log Buffer)
- 모든 변경 (INSERT / UPDATE / DELETE) 의 *흔적 을 디스크 의 *로그 파일 에 쓰기 전 의 *임시 적재.
- 작고 (수 MB), 순차 적. 디스크 의 *순차 쓰기 (sequential write) 가 *랜덤 쓰기 보다 *수십 배 빠른 사실 을 활용.
- commit 의 *순간 — 로그 버퍼 의 *내용 이 *fsync 로 *디스크 의 *로그 파일 에 영구 화. 이 *한 작업 의 완료 가 *트랜잭션 의 *내구성 의 *약속.
이 *두 버퍼 의 *분리 의 *지혜 — 데이터 버퍼 는 *읽기 의 *지연 회피, 로그 버퍼 는 *쓰기 의 *내구성 보장. 두 가지 *완전히 다른 목적 이 각자 의 메모리 영역 으로 분리.
3.2 *프로세스 — *그 일을 *실제로 하는 *손**
도식 에 프로세스 박스 가 3 개 나온다. 현실 의 DBMS 에선 수십 ~ 수백 개 의 *각자 다른 역할 의 프로세스 / 스레드.
클라이언트 의 짝궁 — *Backend Process / Connection Thread
- 각 클라이언트 연결 마다 서버 측 의 *프로세스 (PostgreSQL) 또는 *스레드 (MySQL) 한 개*.
- SQL 텍스트 받음 → 파싱 → 최적화 → 실행 → 결과 반환.
- Buffer Pool 에서 *페이지 를 *읽거나 *변경 함.
- 세션 상태 의 *주인.
내부 일꾼 — *Background Worker / Writer / Checkpointer
| 프로세스 | 역할 |
|---|---|
| Writer / Bgwriter | 수정 된 버퍼 (dirty page) 를 *주기 적 으로 *디스크 의 *데이터 파일 에 플러시 |
| WAL Writer | 로그 버퍼 를 *주기 적으로 *디스크 의 *로그 파일 에 플러시 |
| Checkpointer | 주기 적으로 *모든 dirty page 를 *플러시 + 체크 포인트 기록. 복구 시작 점 의 *명시화 |
| Autovacuum / Purge | MVCC 의 *오래된 버전 정리. PostgreSQL 의 *autovacuum, *Oracle 의 *UNDO retention |
| Stats Collector | 통계 수집 — *Optimizer 의 *재료 |
| Replication Sender | 복제 본 에 *로그 스트리밍 |
각 일꾼 이 *제 책임 만* 한다. Unix 철학 의 *DBMS 판본.
3.3 *CPU — *프로세스 의 *진짜 실행 단위**
도식 에 CPU 박스 가 있는 이유 — DBMS 의 *모든 일 이 결국 *코어 위에서 *돌아간다 는 *상기.
- 프로세스 가 *코어 의 *시간 슬라이스 를 얻어야 *실행.
- 코어 수 = *동시 실행 가능 한 *프로세스 수 의 *상한.
- CPU 100% = *프로세스 들 이 *대기 큐 에서 밀림 — throughput 의 *천장.
- DBMS 의 *튜닝 의 *한 축 — parallel query — 큰 쿼리 의 *여러 코어 분할 실행.
9 년 의 경험 — DB 의 *느림 의 *주된 원인 3 가지 — *(1) Buffer Hit Ratio 부족 (RAM 부족) → 디스크 I/O. (2) 락 대기 (대기 큐 길이). (3) CPU 포화 (parallel query 부족 또는 비효율 쿼리). 대시보드 의 *3 그래프 가 *진단 의 *시작 점.
4. 데이터베이스 의 *4 가지 파일 — 왜 분리 인가**
도식 의 오른쪽 의 *4 개 디스크 통 — 데이터 / 임시 / 시스템 / 로그 — 각자 *다른 목적 의 *다른 수명 의 *다른 접근 패턴.
4.1 데이터 파일 (Data File)
- 진짜 사용자 데이터. *테이블 / 인덱스 의 *영구 저장 *.
- 블록 (4 KB ~ 64 KB) 단위 의 논리 적 페이지 로 조직.
- Random read/write 가 *주된 접근.
| DBMS | 이름 | 위치 |
|---|---|---|
| PostgreSQL | base/<db_oid>/<rel_oid> |
$PGDATA/base/ |
| MySQL InnoDB | .ibd 파일 |
datadir |
| Oracle | Datafile | Tablespace 안 |
특징 — 수 GB ~ TB. 백업 의 *주된 대상. 느린 디스크 (SATA HDD) 에 두면 *전체 DB 가 느려짐.
4.2 임시 파일 (Temp File / Temp Tablespace)
- 큰 정렬 / 큰 join 의 *중간 결과 가 *메모리 에 안 들어가면 *디스크 에 *임시 쓰기.
- 세션 종료 시 *자동 삭제.
- Random read/write 가 *극심.
| DBMS | 이름 |
|---|---|
| PostgreSQL | base/pgsql_tmp |
| MySQL | tmpdir 의 .MYD / .MYI |
| Oracle | TEMP tablespace |
권장 — SSD 의 *별도 디스크. log + data + temp 를 *물리 적으로 분리 하면 I/O 경합 회피.
4.3 시스템 파일 (System Tablespace / Catalog)
- DB 자신 의 *메타 데이터. 테이블 의 정의, *컬럼, *인덱스, *권한, *통계.
- 모든 SQL 의 *시작 이 이 파일 의 조회.
- 작지만 (수 MB ~ 수 GB) *항상 hot.
| DBMS | 이름 |
|---|---|
| PostgreSQL | pg_catalog 스키마 의 시스템 카탈로그 테이블 들 |
| MySQL | mysql 데이터베이스 + INFORMATION_SCHEMA (가상) |
| Oracle | SYSTEM tablespace + DBA_/USER_/ALL_ 뷰 |
결과 — 내가 *SELECT * FROM users 라고 치면 *DBMS 가 *먼저 *시스템 테이블 에서 *“users 라는 테이블 이 *어디 있고 *어떤 컬럼 이 있고 *내가 *권한 이 있는가” 를 확인 한 뒤 *데이터 파일 을 읽는다. 모든 쿼리 의 *2 단계.
4.4 로그 파일 (Redo Log / WAL / Binary Log)
- 모든 변경 의 *순차 적 기록. 내구성 의 *최후 의 보루.
- Sequential write 가 *주된 접근 패턴 — 디스크 의 *최고 속도 활용.
- Crash 시 *복구 의 재료.
| DBMS | 이름 | 용도 |
|---|---|---|
| PostgreSQL | WAL (pg_wal/) |
복구 + Streaming Replication |
| MySQL | Redo Log + Binary Log | Redo: crash 복구. Binary: 복제 + PITR |
| Oracle | Redo Log + Archive Log | Online: crash 복구. Archive: PITR |
9 년 의 *핵심 경험 — 로그 파일 의 *디스크 가 *느리면 *DB 의 *모든 쓰기 가 *느려짐. 내 *2026/06/06 글 etcd 가 HDD 를 미워하는 이유 의 동일 원리.
4.5 *4 가지 분리 의 *물리 적 실천**
production 의 *DBA 의 *전형 적 *배치 :
SSD-A (가장 빠른, NVMe) : 로그 파일 (WAL/Redo)
SSD-B : 데이터 파일 (Data)
SSD-C : 임시 파일 (Temp)
HDD or SSD : 백업 / 아카이브 로그
4 가지 파일 의 *I/O 패턴 의 *극단 적 차이 가 물리 적 분리 의 *완전 한 이유. 경합 회피 = 성능 의 *몇 배 차이.
5. *한 줄 의 SELECT 의 *흐름 — *3 층 의 *왕복**
이제 도식 을 *살아 있는 시퀀스 로 재 구성. 클라이언트 의 *한 줄 SQL 이 어떻게 *3 층 을 *왕복 하는지*.
① [클라이언트] SELECT * FROM orders WHERE id = 1;
↓ (TCP / 프로토콜)
② [인스턴스 - Backend Process]
파싱 → 구문 트리
권한 검증 → 시스템 카탈로그 조회 (System Tablespace)
최적화 → Optimizer 가 Statistics 참조
실행 계획 → "users PK 인덱스 사용"
↓
③ [인스턴스 - Buffer Pool]
인덱스 페이지 *캐시 에 있나?*
있음 → 즉시 사용 (수 µs)
없음 → 데이터 파일 read (다음 단계)
↓
④ [데이터베이스 - Data File]
디스크 read (수 ms)
↓
Buffer Pool 에 *적재*
↓
Backend Process 가 인덱스 트래버스 → 행 위치 발견
↓
다시 데이터 페이지 read (없으면 디스크, 있으면 캐시)
↓
⑤ [인스턴스 - Backend Process]
행 데이터 → 결과 셋 구성
↓ (TCP / 프로토콜)
⑥ [클라이언트] 결과 표시
UPDATE / INSERT / DELETE 의 흐름은 위 의 *④ 이후 가 완전히 다름 :
④' Buffer Pool 의 *해당 페이지 를 *수정* (메모리 만)
↓
⑤' Log Buffer 에 *변경 의 흔적 (Redo)* 기록
↓
⑥' commit 명령 시 → WAL Writer 가 Log Buffer → 디스크 의 로그 파일* fsync
↓
*이 fsync 가 *내구성 의 *약속*. *완료 = commit 의 *공식 완료*.
↓
⑦' 데이터 페이지 (dirty) 는 *나중 에 Bgwriter 가 *조용히 *디스크 에 *플러시*. *서두 르지 않음*.
이 *비대칭 — commit 시 *반드시 *로그 만 *디스크 에 *써짐. 데이터 페이지 의 *디스크 쓰기 는 *지연 가능. Crash 시 *로그 만 있으면 *데이터 의 *재 구성 가능. 이게 *WAL 의 *조용한 천재성.
6. *세 가지 DBMS 의 *동일 패턴 의 *변주**
도식 의 추상화 가 *현실 에서 *어떻게 구체화 되는지 — PostgreSQL / MySQL / Oracle.
6.1 PostgreSQL — *프로세스 모델
- 각 클라이언트 연결 = *별도 OS 프로세스 (fork).
- Buffer Pool = *
shared_buffers(공유 메모리, 보통 RAM 의 25%). - WAL = *
pg_wal/디렉토리 의 연속된 segment 파일. - 시스템 카탈로그 = *
pg_catalog스키마 의 *수십 개 테이블. - Background Process — *background writer, checkpointer, autovacuum launcher, WAL writer, replication sender 등.
특징 — 프로세스 분리 = *안정성 ↑, fork 비용 ↑ = *연결 수 의 *천장 (수천 개). PgBouncer 의 *connection pooler 의 *필수 이유.
6.2 MySQL (InnoDB) — *스레드 모델
- 각 클라이언트 연결 = *별도 OS 스레드.
- Buffer Pool = *
innodb_buffer_pool_size(RAM 의 70~80%). - Redo Log = *
ib_logfile0,ib_logfile1의 순환 사용. - Binary Log = *
mysql-bin.*(복제 + PITR). - Background — *master thread, page cleaner, purge thread, IO thread.
특징 — 스레드 = *경량. 수만 연결 가능. 대신 *한 스레드 의 *충돌 이 *전체 인스턴스 위험.
6.3 Oracle — *극단 적 *완전 분리
- SGA (System Global Area) = 공유 메모리 — Buffer Cache + Redo Log Buffer + Shared Pool + Library Cache + Dictionary Cache.
- PGA (Program Global Area) = 세션 별 *전용 메모리.
- Background — *수십 개 *각자 다른 약자 의 *프로세스 (PMON, SMON, DBWn, LGWR, CKPT, ARCn, …).
- Tablespace = *논리 적 컨테이너 — Data, UNDO, TEMP, SYSTEM, SYSAUX 의 분리.
특징 — 기업 급 의 *극단 적 튜닝 가능 성. 복잡 함 의 대가. 학습 곡선 이 *수년.
6.4 *3 가지 의 *공통 패턴**
| 추상 개념 | PostgreSQL | MySQL InnoDB | Oracle |
|---|---|---|---|
| Buffer Pool | shared_buffers |
innodb_buffer_pool_size |
Buffer Cache (SGA) |
| Log Buffer | WAL Buffer | Log Buffer | Redo Log Buffer (SGA) |
| Backend Process | 프로세스 | 스레드 | Server Process |
| Writer | Background Writer | Page Cleaner | DBWn |
| Log Writer | WAL Writer | (InnoDB master thread) | LGWR |
| Checkpoint | Checkpointer | (master thread) | CKPT |
| 시스템 카탈로그 | pg_catalog | mysql + INFORMATION_SCHEMA | SYSTEM tablespace + DBA_/USER_ 뷰 |
| 로그 파일 | pg_wal/ | ib_logfile + mysql-bin | Redo + Archive Log |
결론 — 3 가지 DBMS 가 *역사 적 *진화 가 *다르 지만 *추상 개념 의 *공통 골격 이 *동일. 도식 의 *추상화 가 *DBMS 전체 의 *공통 언어.
7. *백엔드 개발자 가 *이 구조 를 *알아야 하는 *5 가지 이유**
9 년 의 *경험적 *결정 적 적용 점.
7.1 *연결 풀 의 *크기 결정**
- 서버 의 *Backend Process / Thread 수 의 상한 (예: PostgreSQL 의
max_connections = 200). - 내 *애플리케이션 의 *HikariCP
maximumPoolSize가 그 상한 의 *부분 만 차지 해야*. - 너무 크면 *DB 의 프로세스 폭발 + 메모리 폭발. 너무 작으면 *애플리케이션 의 *대기 큐 폭발*.
- Hikari 와 *서버 max_connections 의 *수학 적 관계 의 *이해 가 *9 년 의 *반복 적 *학습 점.
7.2 *N+1 의 *진단**
- Buffer Pool 의 *Hit Ratio 가 95 % 이상 인데 *왜 *느린가. 그게 *N+1 의 *전형 — Buffer 의 캐시 효율 이 *완전 함 에도 *너무 *많은 쿼리 의 *순차 적 실행.
- 프로세스 가 *순차 적 으로 *수백 번 *Buffer 와 *왕복 — 대부분 의 시간 이 *각 쿼리 의 *수십 µs 의 *합산.
- 해결 = *fetch join / batch fetching — 왕복 의 횟수 자체 를 *줄임.
7.3 *Long Transaction 의 *위험**
- 내 트랜잭션 이 *수 분 동안 *열려 있으면 :
- MVCC 의 *오래된 버전 이 *autovacuum / purge 의 *대상 에서 *제외. 데이터 파일 의 *부풀어 오름.
- Buffer Pool 의 *오래 안 쓰이는 페이지 가 *고정 되어 *다른 쿼리 의 *캐시 공간 잠식.
- Log Buffer 가 *내 트랜잭션 의 *모든 변경 의 *로그 보관 강제. Log Buffer 부족 가능.
- 교훈 — 트랜잭션 의 *수명 을 *짧게. 비 즈 니스 로직 의 *경계 = 트랜잭션 의 *경계.
7.4 *복제 지연 의 *진단**
- Master 의 *Log Writer 가 WAL 을 *디스크 에 쓰자 마자 *Replication Sender 가 Replica 로 *스트리밍.
- Replica 의 *Log Apply Process 가 그 WAL 을 *재생.
- 지연 의 *원인 — Sender 의 *네트워크 / Replica 의 *Apply CPU / Replica 의 *Buffer Pool 의 *경합.
- 어느 단계 의 *병목 인지 를 분리 진단 해야 해결 가능.
7.5 *백업 / 복구 의 *원리**
- Hot backup = *데이터 파일 + 그 시점 부터 의 *WAL 의 합본 보관.
- 복구 = *데이터 파일 복원 → *WAL 재생 → *목표 시점 (Point-In-Time Recovery).
- WAL 의 *완전 함 이 *복구 의 *완전 함 의 *전제 조건.
9 년 의 *결론 — DBMS 의 *구조 의 *이해 가 *백엔드 의 *9 가지 *어려운 문제 (N+1, 동시성, 락 대기, 풀 고갈, 복제 지연, 백업, 보안, 성능, 비용) 의 공통 근본 의 *언어.
8. *결론 — *도식 의 *4 가지 의 *영원한 의미**
처음 그림 5-2-1 의 4 가지 영역 을 다시 본다.
- 클라이언트 — 내 가 *항상 만지는 곳. Spring Boot, IDE, batch — 모두 *여기.
- 인스턴스 의 *메모리 — 디스크 의 *느림 을 *덮는 *얇은 마법.
- 인스턴스 의 *프로세스 + CPU — SQL 을 *기계 어 로 *번역 하고 실행 하는 *살아 있는 손.
- 데이터베이스 의 *4 가지 파일 — 데이터 / 임시 / 시스템 / 로그 의 각자 의 *책임 의 *분리.
이 *4 가지 가 *현대 DBMS 의 *근본. PostgreSQL 의 *2026 년 *최신 버전 도, *MySQL 9 도, *Oracle 23ai 도 — 모두 *이 골격 의 변주.
“DBMS 를 *공부 한다” 는 것은 SQL 의 *수십 개 함수 를 *외우는 것 이 아니라 이 *3 층 의 *각 박스 의 *책임 의 *경계 와 *그 *분리 의 *이유 를 *깊이 이해 하는 것**. *그러면 *내 SQL 한 줄 이 어떻게 흐르는지 가 눈 에 보인다. 그 시야 가 *9 년 의 *모든 디버깅 의 *시작 점.
다음 으로 *권 하는 읽기**
- 원작 의 *원작 — Hellerstein, Stonebraker — *“Architecture of a Database System” (2007, Foundations and Trends in Databases). 학문 적 *밑바닥.
- PostgreSQL 의 *내부 — PostgreSQL 공식 문서 의 *Chapter 70 Internals 부분. 오픈소스 의 *완전 한 공개.
- Oracle 의 *Concepts Guide — 900 페이지 의 *교과서. 기업 급 의 *시야.
- Designing Data-Intensive Applications (Kleppmann, 2017) — DBMS 의 *분산 적 *확장. 분산 시스템 의 *언어 까지.
- 자매편 — 내 HikariCP 깊이 글 + MySQL 의 7 가지 안정성 기둥.
다음 글 — 이 *3 층 의 *각 박스 가 *production 에서 *깨지면 *어떻게 *진단 하는지 의 5 가지 사고 사례 — 곧.