*AI 프롬프트* 의 *7 가지 기호* — *기호 한 개* 가 *지시* 의 *정밀도* 를 *바꾼다*
“같은 요청을 *같은 LLM 에 보냈는데* 결과 가 완전히 다르다. 왜 인가?”
답은 *문장의 *구조 에 있다. *자연어 만의 프롬프트 는 모호. 기호 가 들어가는 순간 *지시 의 경계 가 *선명해 진다. 오늘 글 은 *7 가지 기호 가 왜 효과 적 인지 의 분석.
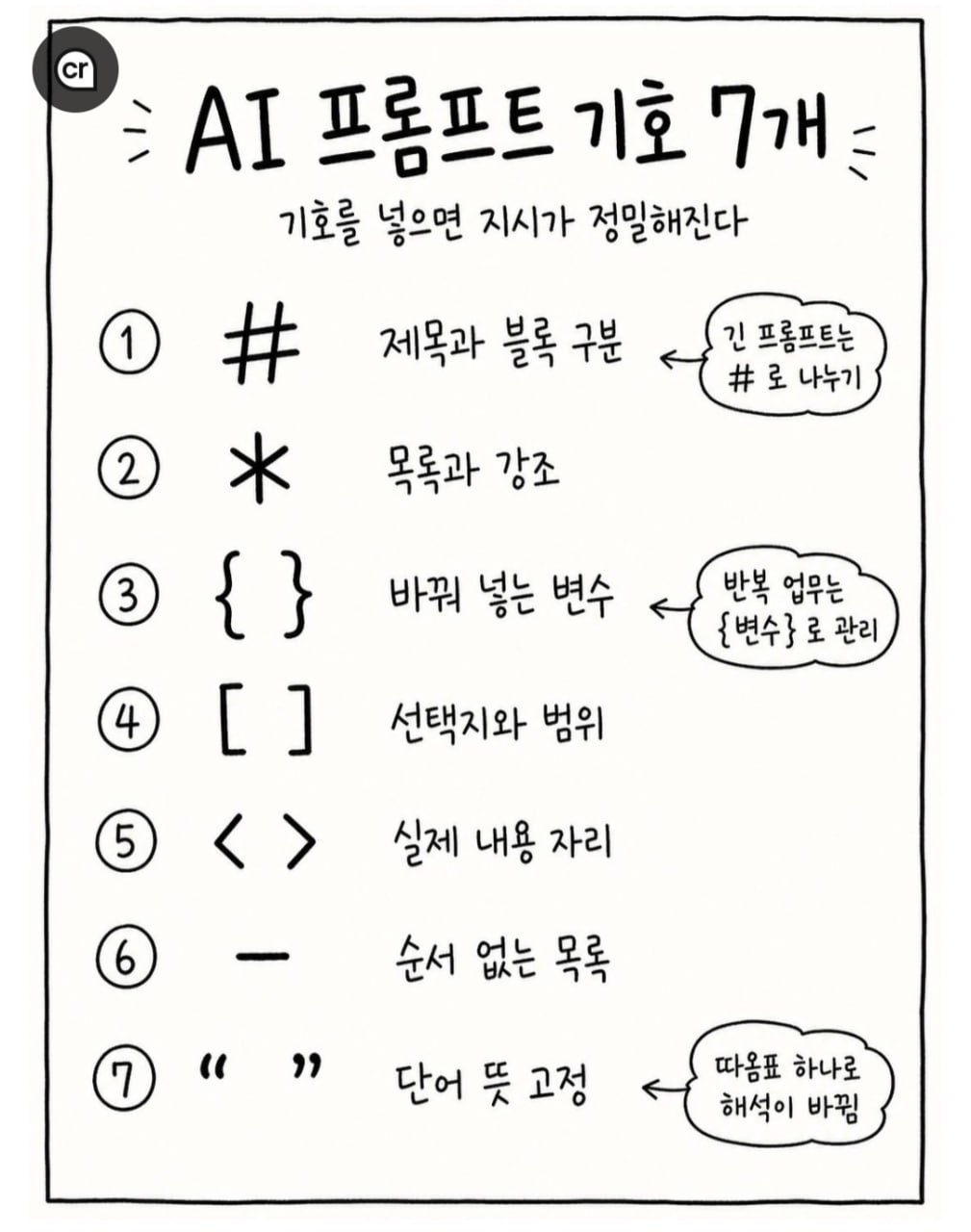
위 그림 의 7 가지 기호 — #, *, {}, [], <>, —, " " — 가 AI 와 의 *대화 의 *효율 을 *극적으로 바꾼다.
내 Claude Code 운영 + Settlement / Lemuel / Jabis 시스템 의 *AI 도움 + 블로그 글 작성 의 패턴. 모두 *위 7 가지 기호 의 의식적 활용. 우연이 아니라 *학습된 패턴. 이 글에서 각 기호 의 *원리 와 *실전 예시 를 정리.
TL;DR — 한 줄 결론
LLM 은 *마크다운 으로 *학습 된 모델. 기호 가 *내부 의 *주의 (attention) 의 경계 를 그어 준다. 7 가지 기호 = *7 가지 *구조 적 지시. # 은 섹션, * 은 강조, {} 는 변수, [] 는 선택지, < > 는 플레이스홀더, — 는 목록, ” “ 는 고정 의미. 기호 1 개 가 *모호 한 자연어 를 명확 한 명령 으로 변환. 내 *블로그 의 *별표 강조 도 2 번 기호 의 *적용. 프롬프트 엔지니어링 의 *기본기 = *마크다운 의 *문해력.
1. 왜 기호 가 *LLM 에게 *통하는가 — 학습 데이터 의 진실**
LLM 은 *어디서 배웠는가 — 인터넷 의 *수조 토큰. 그 대부분 이 *마크다운 또는 *마크다운 - 유사 형식**:
- GitHub README / 위키 / 블로그
- StackOverflow 답변
- 기술 문서
- Reddit / HackerNews 토론
즉 LLM 의 *문법 의 절반 이 *마크다운. 내가 마크다운 기호 를 쓰면 *LLM 의 *학습 시 의 *구조 와 매칭. 내부 의 *주의 (attention) 가 *정렬.
flowchart LR
P[자연어 프롬프트<br/>"이걸 정리해"] --> A1[LLM 의 ambiguity<br/>여러 해석 가능]
A1 --> R1[다양한 출력<br/>예측 불가]
PS[기호 포함 프롬프트<br/>"# 정리<br/>* 항목 1<br/>* 항목 2"] --> A2[LLM 의 정렬<br/>섹션 + 목록 구조 인식]
A2 --> R2[일관 된 출력<br/>예측 가능]
classDef bad fill:#5f1e1e,stroke:#ef4444,color:#fff
classDef good fill:#1f3f1f,stroke:#22c55e,color:#fff
class P,A1,R1 bad
class PS,A2,R2 good
기호 의 진짜 의미 — “내가 *말로만 *지시 하지 않고 *형식 으로도 지시 한다”. 형식 자체 가 *명령.
2. 기호 1 — # — *제목 과 *블록 의 *구분**
2.1 의미
# 은 마크다운 의 *제목. 섹션 의 시작. LLM 에게 *“여기 부터 *새 맥락” 이라는 강한 신호.
2.2 나쁜 예 vs 좋은 예
나쁨 — 모든 게 *한 문단 :
이 시스템 분석해줘 코드도 보고 보안 관점도 보고 성능도 보고 결과는 한국어로 알려주고 마크다운으로 정리하고
좋음 — 섹션 분리 :
# 분석 대상
order-service 의 결제 API 흐름
# 검토 관점
1. 코드 품질
2. 보안 (OWASP Top 10)
3. 성능 (N+1 / Connection pool)
# 출력 형식
* 한국어
* 마크다운
* 각 관점 별 *별도 섹션*
LLM 이 “이게 분석 대상이구나 → 그 다음이 관점이구나 → 그 다음이 형식이구나” 로 구조 적 으로 *추론. 모호 함 의 *제거.
2.3 내 *Claude Code 의 *시스템 프롬프트 의 섹션 구조**
내가 오늘 *새벽 운영 중 사용한 프롬프트 들 의 공통 패턴 — 항상 # 섹션 분리:
# 컨텍스트
지금 louise 노드 24 시간 다운. 모든 포트 refused.
# 작업
원격 진단 + 영향 도메인 식별
# 제약
- 클러스터 직접 변경 금지 (read-only)
- 새벽 시간 — 무리한 액션 X
- 결과 텔레그램 보고
# 출력
1. 진단 요약
2. 영향 범위
3. 권장 액션 (선택지)
결과 — Claude 가 *각 섹션을 *정확히 분리 해서 응답. 제약 누락 없음.
3. 기호 2 — * — *목록 과 *강조**
3.1 두 가지 용법
* 의 2 중 의미 :
* 항목— 목록 (line start)*단어*— italic / 강조 (inline)**단어**— bold / 강한 강조
LLM 의 학습 에서 * 가 두 의미 모두 출현 빈도 높음 → 문맥 으로 자동 구분.
3.2 내 블로그 의 *별표 강조 의 이유**
내 블로그 글 의 모든 별표 강조 — 2 번 기호 의 직접 적용. 왜 :
- 시선 의 *흐름 의 제어 — 중요 한 단어 만 *눈에 들어옴
- AI 가 *나중에 *내 글 을 학습 할 때 어떤 단어 가 *중요 한지 신호
- 읽는 사람 의 *스캐닝 (skim) 의 가속
- 내 사고 의 *구조 의 *외화
글 자체 가 *이 글 의 *2 번 기호 의 *대규모 적용 예시. 지금 이 문단 만 봐도 *별표 가 수십 개. 각 의 *의도 가 있다.
3.3 목록 의 *3 가지 변형
* 일반 목록
- 동일 (대시 와 별표 호환)
+ 동일 (드물게)
LLM 은 3 가지 다 인식. 일관성 만 유지하면 됨.
4. 기호 3 — { } — *바꿔 넣는 *변수**
4.1 템플릿 패턴 의 *핵심**
{회사명} 의 {도메인} 시스템 분석 :
- 코드 리뷰 관점
- {기준 일자} 까지 의 변경 사항
- 출력 언어: {언어}
반복 업무 에서 프롬프트 의 *템플릿화. {변수} 만 갈아 끼우면 *동일 품질 의 *반복 적 응답.
4.2 내 *Settlement 운영 의 *반복 프롬프트**
# 정산 알람 분석
알람: {알람_이름}
namespace: {네임스페이스}
시간: {ts}
## 진단 절차
1. {네임스페이스} 의 pod 상태
2. 관련 deployment 의 events
3. log 의 최근 ERROR
4. 백엔드 의 actuator/health
## 출력
- 원인 추정 + 증거
- 권장 액션 (선택지)
- 영향 범위
- 텔레그램 회신용 요약
매 번 *알람 의 변수 만 갈아 끼움. 내 *알람 응답 의 *일관성 의 기반.
4.3 변수 의 *이름 규칙
✅ {snake_case}
✅ {kebab-case}
✅ {camelCase}
✅ {한국어}
LLM 은 *모두 인식. 프로젝트 의 일관성 이 더 중요.
5. 기호 4 — [ ] — *선택지 와 *범위**
5.1 선택지 의 *명시**
응답 형식 선택:
[A] 한 줄 요약
[B] 3 줄 요약
[C] 전체 분석
당신 의 선택: [B]
LLM 이 *선택지 의 명시 적 *경계 를 본다. “애매 한 중간 길이” 가 아니라 *3 줄 로 정확히.
5.2 범위 의 *지정**
시간 범위: [2026-06-20, 2026-06-25]
점수 범위: [1, 10]
파일 범위: [src/main/**/*.kt]
시작 - 끝 의 명시 적 경계. LLM 이 *bound 이해.
5.3 내 *코드 리뷰 의 *선택지 패턴**
# 리뷰 모드 선택
[lightweight] - 명백한 버그 만
[standard] - 코드 품질 + 안전성
[deep] - 위 + 아키텍처 + 성능 + 보안
# 출력 형식
[markdown / json / inline-comment]
# 우선순위
[critical / major / minor / nit]
Claude 가 *명확히 *선택. 애매 한 응답 의 *원천 제거.
6. 기호 5 — < > — *실제 내용 의 *자리**
6.1 플레이스홀더 의 *진짜 의미**
{} 가 변수 라면 <> 는 플레이스홀더 — “여기에 *실제 내용 이 들어 갑니다”. *프롬프트 의 *구조 와 예시 의 경계.
# 작업
다음 코드 의 *N+1 query* 식별 :
<code>
// 여기에 실제 코드 붙여 넣기
</code>
# 출력
- 발견 된 위치 (line number)
- 수정 제안
LLM 이 사이 가 *실제 분석 대상 이고 그 외 는 *지시 임을 명확 히 분리.
6.2 Claude 의 *XML-like 태그 친화성**
Anthropic 의 공식 가이드 — Claude 는 *XML 태그 에 *특별 히 잘 반응. 학습 데이터 에 Claude 자체 의 *문서 가 *영향 을 미쳤을 가능성.
<context>
사용자 는 backend developer. Spring Boot 중심.
</context>
<task>
N+1 query 식별 + 수정
</task>
<input>
@Entity
class Order { ... }
</input>
<output_format>
1. 문제 위치
2. 원인
3. 수정 코드 (diff)
</output_format>
Claude 의 응답 품질 이 현저히 높아 짐. Anthropic 의 권장 패턴.
7. 기호 6 — — — *순서 없는 *목록 (또는 *대시)**
7.1 — 의 두 가지 의미**
- 대시 — 강조 / 부연 — 마치 *문장 의 *호흡 같은 분리자
- — 항목 — 순서 없는 목록 의 *대안 표기
7.2 내 글 의 *대시 사용 패턴**
이 글 의 모든 *— 가 기호 6 의 적용. 왜 :
- 문장 의 *호흡 의 *제어
- “즉” / “그러니까” / “다른 말로” 의 조용 한 대체
- 읽는 속도 의 *완급
LLM 에게 — 다음 은 “이전 의 *부연 설명” 으로 학습 됨. 내 의도 가 *AI 에게 잘 전달.
7.3 — vs — vs - 의 차이*
- 하이픈 (hyphen, U+002D) — *목록*
– en-dash (U+2013) — *범위* (예: 2026–2027)
— em-dash (U+2014) — *부연 / 강조 의 분리자*
LLM 은 *3 가지 다 의미적으로 *구분. 내 글 의 *— 는 *em-dash. 부연 의 호흡.
8. 기호 7 — " " — *단어 뜻 의 *고정**
8.1 따옴표 의 *마법**
그림 의 부제 — “따옴표 하나로 *해석이 바뀜”. 정확함.
비교 :
사용자가 admin 에 접근했다
사용자가 "admin" 에 접근했다
첫 번째 — admin 의 *역할 가진 사용자 가 접근 두 번째 — admin 이라는 *문자열 또는 계정 에 접근
따옴표 하나 가 *문맥 을 *완전히 바꿈.
8.2 기술 용어 의 *고정**
배포 가 "blue-green" 인 데 ...
* "Outbox" 패턴 을 적용 ...
* "settlement-service" 가 library jar 로 ...
특정 용어 가 기술적 명사 임을 AI 에게 명시. 오해 의 여지 제거.
8.3 Claude 의 *quote 인식
Claude 는 큰 따옴표 / 작은 따옴표 / 백틱 을 모두 *별도 의 *문자열 표시 로 인식. 백틱 은 코드 / 변수, 큰 따옴표 는 문자열 또는 인용. 작은 따옴표 는 덜 강한 강조.
`code_variable` — 코드
"문자열 또는 *정확 한 용어" — 문자열
'덜 강한 인용 또는 옵션' — 옵션
9. 7 가지 의 *시너지 — *완성 된 프롬프트 의 예**
내 Settlement 의 *월 정산 분석 을 Claude 에 시킨 *프롬프트 — *7 가지 의 *동시 적용**:
# 정산 분석 요청
## 컨텍스트
{회사} 의 settlement-service 의 월 정산 배치.
<context>
- DB: PostgreSQL 17
- 모듈: settlement-service (library jar, order-service 에 번들)
- ORM: JPA
- 데이터 량: payments 약 {row_count} row
</context>
## 작업
다음 SQL 을 *분석* 하고 *최적화* 제안:
<sql>
SELECT seller_id, SUM(amount), SUM(fee)
FROM payments
WHERE status = "CAPTURED"
AND created_at BETWEEN [{start}, {end}]
GROUP BY seller_id;
</sql>
## 검토 관점
- *Index 사용 가능성*
- *커버링 인덱스* 의 적용
- *파티션 가지치기*
- *EXPLAIN ANALYZE* 의 예상 결과
## 출력 형식
[markdown]
1. 현재 쿼리 의 *예상 비용*
2. 인덱스 권장 (CREATE INDEX 문)
3. EXPLAIN 의 예상 변화
4. 추가 최적화 후보 ({카디널리티}, {row_count} 별 분기)
7 가지 의 *모두 사용:
- # — 섹션 (5 개)
- * — 강조 + 목록
- {} — 변수 (회사, row_count, start, end, 카디널리티)
- [] — 범위 + 출력 형식 선택
- <> — 코드 자리 (XML-like)
- — — 부연 / 강조 분리
- ” “ — 기술 용어 고정 (“CAPTURED”)
Claude 의 응답 — 놀라울 정도 로 정확. 내가 *기대 한 *모든 섹션. 놓침 없음.
10. 체크리스트 — *내 다음 프롬프트 점검**
내 프롬프트 를 *보내기 전 에 5 초 점검:
- # 으로 섹션 을 *나눴는가 (긴 프롬프트)
- * 으로 중요 한 단어 를 *강조 했는가
- 반복 가능 한 부분 을 {} 의 변수 로 추출 했는가
- 선택지 를 [] 로 명시 했는가
- 입력 자리 를 <> 또는 ``` 로 경계 지었는가
- 목록 의 *— 가 호흡 의 *완급 을 만드는가
- 기술 용어 를 ” “ 로 고정 했는가
3 가지 이상 YES 면 프롬프트 의 정밀도 가 2 배 이상. 내 *Claude 와의 협업 의 *체감 차이.
11. 맺음 *— *프롬프트 의 *문해력
“프롬프트 엔지니어링” 이라는 단어 가 과하게 거창 하게 들린다.
진짜 본질 — 마크다운 의 *문해력 + 7 가지 기호 의 *의식 적 활용.
LLM 이 *마크다운 으로 *학습 된 모델 이라는 사실 을 받아 들이면 — 마크다운 의 *문법 의 *모든 기호 가 *나의 *지시 의 *도구 가 된다. 기호 가 *말 보다 *강한 신호.
내 블로그 의 *별표 강조, # 섹션, — 부연, 코드 의 ``` — 전부 *7 가지 기호 의 *의식 적 적용. 우연 의 패턴 이 아니라 *학습 된 *AI 협업 의 *문법.
내일 *내 Claude 에게 *무언 가 시킬 때 — 위 7 가지 의 *최소 *3 가지 를 동시 적용. 체감 의 차이 가 명확. AI 의 *주의 가 *내 의도 에 정렬.
프롬프트 엔지니어링 의 *기본기 가 마크다운 의 문해력. 그게 *오늘 글의 *진짜 결론.
부록 — 오늘 *3 분 안 에 해볼 수 있는 *3 가지**
-
내 지난 프롬프트 의 *재 작성 — 기호 없이 던진 프롬프트 1 개 를 7 가지 기호 활용 의 형태 로 다시 작성 해 보고 응답 비교
-
내 반복 업무 의 *템플릿화 — 주 1 회 이상 하는 *AI 요청 을 #, {}, <> 활용 의 템플릿 으로 저장
-
내 블로그 / 문서 의 *별표 강조 도입 — 읽는 사람 의 *스캐닝 의 가속 + AI 의 *학습 시 의 *중요도 신호
관련 글
- 바이브 코딩 과 AI 시대 시니어 개발자 의 7 가지 기준 — AI 가 *클래스 를 만들 어도 *시야 는 *내가. 프롬프트 의 *책임
- 객체지향 의 *핵심 가치 — 역할 · 책임 · 협력 — 역할 의 *추상화 가 *프롬프트 의 *변수 와 동일 의 원리
- 서버 의 *기본기 — 한 요청 의 여정 — layer 의 시야 — 프롬프트 도 같은 *원리
- 8 가지 체크리스트 로 *settlement 자가 검수 — 체크리스트 의 *명시 적 구조 의 프롬프트 적 가치