*Kubernetes 의 로드밸런서* — *L4 (Service) vs L7 (Ingress)* 의 *네트워크 계층* 과 *알고리즘 의 *진실*
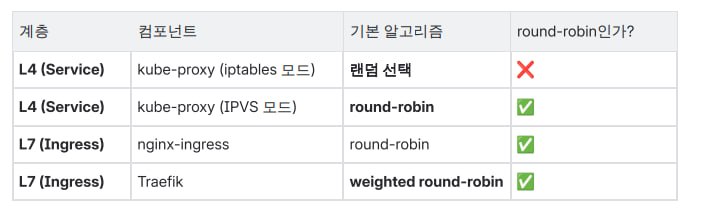 L4 (Service) 의 kube-proxy 는 iptables 모드 = *랜덤 선택, IPVS 모드 = round-robin. L7 (Ingress) 의 nginx-ingress = round-robin, Traefik = weighted round-robin. 같은 “로드밸런서” 라도 계층과 도구 에 따라 알고리즘 이 다르다.*
L4 (Service) 의 kube-proxy 는 iptables 모드 = *랜덤 선택, IPVS 모드 = round-robin. L7 (Ingress) 의 nginx-ingress = round-robin, Traefik = weighted round-robin. 같은 “로드밸런서” 라도 계층과 도구 에 따라 알고리즘 이 다르다.*
“K8s 의 *Service 와 *Ingress 가 *둘 다 *load balance 한다” — 이 한 줄 은 *반쪽 진실. 둘 은 *다른 OSI 계층, 다른 도구, 다른 알고리즘 으로 load balance 한다.
“Service 가 *round-robin 으로 분산 한다” — 이 말 도 위험 한 일반화. kube-proxy 가 *iptables 모드 라면 round-robin 이 아니라 *확률 기반 *랜덤 이고, IPVS 모드 가 되어야 진짜 round-robin. 같은 Service 추상화 가 내부 구현 에 따라 *완전 다른 동작.
Ingress 도 같다. nginx-ingress 의 기본 은 round-robin 이지만, Traefik 의 *기본 은 weighted round-robin. 동일 한 L7 Ingress 라도 컨트롤러 마다 *기본 알고리즘 다름.
이 글은 위 그림 의 4 행 의 *왜 그렇게 다른가 부터 시작해서 L4 / L7 의 *본질 적 차이, kube-proxy 의 *3 모드 진화, IPVS 의 *8 종 알고리즘, Ingress controller 비교, 외부 LB / 클라우드 LB, 우리 6 노드 K3s 클러스터 의 *실제 사용 까지 분해 한다.
내 10 편 인프라 연작 의 후속편 :
오케스트레이션 글 에서 Service / Ingress 를 *간단히 언급 했다면, 이 글 은 그 둘 의 *내부 동작 의 깊이.
TL;DR — 한 줄 결론
K8s 의 로드밸런서 는 *한 가지 가 아니다 — L4 의 *Service (kube-proxy) 와 L7 의 *Ingress 가 각자 다른 OSI 계층 에서 *다른 알고리즘 으로 *load balance. kube-proxy 의 *iptables 모드 는 round-robin 이 아니라 *확률 기반 *랜덤. IPVS 모드 로 가야 진짜 round-robin + 8 종 알고리즘. L7 Ingress 는 컨트롤러 마다 *기본 다름 — nginx round-robin, Traefik weighted round-robin. Service Mesh (Istio, Linkerd) 는 Envoy 사이드카 로 수십 가지 알고리즘 (consistent hash, locality-aware, outlier detection) 제공. 클라우드 의 *NLB / ALB 와 온프렘 의 *MetalLB / Klipper-LB 가 그 위 또는 옆 에 *얹힌다. 어느 계층 / 어느 알고리즘 을 선택 할지 는 워크로드 의 *분포 / 세션 특성 / 외부 노출 요구 의 함수.
1. Service vs Ingress — *L4 vs L7 의 *본질**
1.1 OSI 계층 의 *차이**
[Layer 7 — Application] HTTP, HTTPS, gRPC ← Ingress, Service Mesh
[Layer 6 — Presentation] TLS, SSL
[Layer 5 — Session]
[Layer 4 — Transport] TCP, UDP ← Service, kube-proxy
[Layer 3 — Network] IP, ICMP ← CNI (Calico, Flannel)
[Layer 2 — Data Link] Ethernet, ARP
[Layer 1 — Physical] cables, NIC
L4 와 *L7 의 결정 적 차이 : L4 는 *패킷 의 *5-tuple (src IP, src port, dst IP, dst port, protocol) 만 본다. *L7 은 *HTTP method / path / header / cookie / body 까지 본다*.
1.2 L4 (Service) 의 *책임**
- Pod IP 가 *동적 임 — 재시작 시 새 IP.
- N 개 의 Pod 을 *하나의 *가상 IP (ClusterIP) 로 추상화.
- 클라이언트 가 *ClusterIP : Port 로 보내면 kube-proxy 가 *백엔드 Pod 중 *하나로 *전달.
1.3 L7 (Ingress) 의 *책임**
- 외부 HTTP 요청 을 클러스터 내 Service 로 라우팅.
- Host header, path, header 기반 라우팅.
- TLS termination.
- URL rewrite, redirect, rate limit, auth.
→ Ingress 는 *Service 의 *위에 *얹힌다. L7 → L4 → Pod 의 2단 계 라우팅.
1.4 왜 *둘 다 *필요한가
[Internet]
↓
[Ingress (L7)] — *Host / path 기반 라우팅*
↓ 결정: jen.lemuel.co.kr → settlement-service
↓
[Service (L4)] — *settlement-service ClusterIP : 8080*
↓ kube-proxy 가 *백엔드 Pod 중 하나로 전달*
↓
[Pod]
외부 사용자 는 L7 (Ingress) 만 본다. 내부 서비스 끼리 통신 은 L4 (Service) 만으로 충분.
2. L4 — *kube-proxy 의 *3 모드 진화
2.1 kube-proxy 의 *역할
각 노드 에 *DaemonSet 으로 실행. Service 의 *가상 IP → 실제 Pod IP 의 변환 룰 을 유지.
[Pod on node A]
↓ ClusterIP 10.43.0.5:8080 으로 요청
[kube-proxy on node A]
↓ iptables / IPVS 룰 따라
↓ 백엔드 중 *하나* 선택
[Pod on node B (또는 같은 노드)]
2.2 Mode 1 — *userspace (deprecated, 2015 ~ 2017**)
- kube-proxy 가 *userland TCP proxy — 모든 패킷 이 *userland 에 올라옴.
- 느림. 지금 은 사용 안 함.
2.3 Mode 2 — *iptables (default, 2017 ~)**
# iptables 룰 예 — 3 백엔드 의 *확률 분배*
-A KUBE-SVC-XXX -m statistic --mode random --probability 0.333 -j KUBE-SEP-A
-A KUBE-SVC-XXX -m statistic --mode random --probability 0.500 -j KUBE-SEP-B
-A KUBE-SVC-XXX -j KUBE-SEP-C
★ 핵심 진실 — iptables 는 “round-robin” 이 *아니다
위 그림 의 *L4 (Service) — kube-proxy (iptables) — 랜덤 선택 — ❌ 의 진짜 의미.
- 각 룰 이 *확률 (
--probability) 로 매칭. - 3 백엔드 면 *첫 룰 33%, 둘째 룰 50% (남은 중에서), 셋째 룰 fallthrough.
- 결과 적으로 long-run 에서 *각 백엔드 *균등 하지만 short-run 에선 *우연 의 *클러스터링.
- 진짜 round-robin (1→2→3→1→2→3) 이 아님. 동전 던지기 (random).
iptables 모드 의 문제
- 수천 Service 의 *수만 룰 — iptables 룰 평가 가 *O(N) 선형 탐색.
- 룰 업데이트 시 전체 chain 다시 빌드 — 대규모 클러스터 에서 *수 분 소요.
- 부드러운 weighted load balancing 어려움.
2.4 Mode 3 — *IPVS (2018 ~, kernel 4.0+ 권장)**
Linux Virtual Server — kernel 의 L4 load balancer 모듈. iptables 와 *별개 의 *전문 도구.
# IPVS 의 round-robin (rr) 모드
ipvsadm -A -t 10.43.0.5:8080 -s rr
ipvsadm -a -t 10.43.0.5:8080 -r 10.42.1.10:8080
ipvsadm -a -t 10.43.0.5:8080 -r 10.42.2.10:8080
ipvsadm -a -t 10.43.0.5:8080 -r 10.42.3.10:8080
IPVS 의 8 종 알고리즘
| 코드 | 이름 | 의미 |
|---|---|---|
| rr | round-robin | 순차 적 분배. 기본. |
| wrr | weighted round-robin | 가중치 * 순차. 노드 spec 다를 때. |
| lc | least connection | 현재 연결 적은 백엔드 우선. long-lived 연결 에 유리. |
| wlc | weighted least connection | lc + 가중치. |
| lblc | locality-based least connection | 동일 클라이언트 IP → 동일 백엔드 (sticky). |
| lblcr | lblc with replication | lblc + replica 그룹. |
| dh | destination hash | 대상 IP hash. |
| sh | source hash | source IP hash → session sticky. |
| sed | shortest expected delay | 예측 지연 최소. |
| nq | never queue | idle 백엔드 우선. |
→ 위 그림 의 *kube-proxy (IPVS 모드) — round-robin — ✅ 는 기본값 rr. 그러나 *원하면 *8 종 알고리즘 자유 선택.
IPVS 의 우위
- O(1) 룰 평가 — hash table 기반.
- 연결 추적 — least connection 같은 상태 기반 알고리즘 가능.
- 대규모 클러스터 에서 *throughput 우위.
활성화
# kube-proxy ConfigMap
mode: ipvs
ipvs:
scheduler: rr # or wrr, lc, wlc, sh, dh, ...
→ K3s 도 --kube-proxy-arg=proxy-mode=ipvs 로 활성화 가능. 우리 클러스터 는 *iptables 모드 (k3s 기본).
3. L7 — *Ingress Controller 비교
3.1 Ingress 의 *기본
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-app
annotations:
cert-manager.io/cluster-issuer: letsencrypt-prod
spec:
ingressClassName: nginx # or traefik, contour, etc.
tls:
- hosts: [jen.lemuel.co.kr]
secretName: jen-tls
rules:
- host: jen.lemuel.co.kr
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: settlement-service
port: { number: 8080 }
→ Ingress 자체 는 *명세 (spec). 실제 트래픽 처리 는 Ingress Controller (구현체) 가.
3.2 주요 Ingress Controller
| Controller | 기본 알고리즘 | 사용 사례 |
|---|---|---|
| nginx-ingress | round-robin | 가장 흔함, 우리 클러스터 의 선택 |
| Traefik | weighted round-robin | 동적 service discovery 친화 |
| HAProxy Ingress | round-robin | 고성능 / 정교한 정책 |
| Contour (Envoy 기반) | round-robin / random | gRPC, HTTP/2 강력 |
| Istio Gateway | round-robin / locality / 등 | Service Mesh 의 일부 |
| GKE Ingress | round-robin | GCP managed |
| AWS ALB Ingress | least-outstanding-requests | EKS managed |
| Azure Application Gateway | round-robin | AKS managed |
3.3 nginx-ingress — *가장 흔한 선택
# nginx upstream 의 *기본 round-robin*
upstream settlement-service {
server 10.42.1.10:8080;
server 10.42.2.10:8080;
server 10.42.3.10:8080;
}
# 첫 요청 → .1.10, 둘째 → .2.10, 셋째 → .3.10, 넷째 → .1.10 (진짜 RR)
→ 위 그림 의 *nginx-ingress — round-robin — ✅ 의 근거.
변경 가능한 알고리즘
# annotation 으로 조정
nginx.ingress.kubernetes.io/load-balance: "ewma" # exponentially weighted moving average
nginx.ingress.kubernetes.io/load-balance: "round_robin" # 기본
Session affinity (sticky)
annotations:
nginx.ingress.kubernetes.io/affinity: "cookie"
nginx.ingress.kubernetes.io/session-cookie-name: "route"
nginx.ingress.kubernetes.io/session-cookie-max-age: "3600"
→ 쿠키 기반 session sticky. 장바구니 / 로그인 세션 의 동일 백엔드 보장.
3.4 Traefik — *Rancher 친화 선택
Traefik Labs 의 Go 기반 dynamic-discovery proxy. K3s 의 *기본 Ingress 가 Traefik.
# Traefik 의 weighted round-robin
apiVersion: traefik.io/v1alpha1
kind: TraefikService
metadata:
name: weighted-service
spec:
weighted:
services:
- name: my-service-v1
weight: 3
- name: my-service-v2
weight: 1
# → v1 : v2 = 3 : 1 비율
→ 위 그림 의 *Traefik — weighted round-robin — ✅ 의 근거. 기본 으로 weighted 지원.
Traefik 만의 강점:
- Service discovery 자동 (Docker, K8s, Consul).
- Mid-tier middleware — auth, rate limit, IP whitelist 가 built-in.
- Dashboard UI 기본 제공.
4. Service Mesh — *Envoy 의 *수십 가지 알고리즘**
4.1 Service Mesh 의 *위치
[L7 Ingress (외부 → 클러스터)]
↓
[Service (L4 ClusterIP)]
↓
[★ Sidecar (Envoy) — L7 라우팅 / mTLS / metric ★]
↓
[Pod]
Istio / Linkerd / Consul Connect / Cilium Service Mesh — 모든 Pod 마다 *Envoy 또는 자체 proxy 가 *sidecar 로 주입.
4.2 Envoy 의 *알고리즘
| 알고리즘 | 의미 |
|---|---|
| round-robin | 순차 |
| random | 무작위 (iptables 와 비슷) |
| least-request | 최소 요청 (P2C — Power of Two Choices) |
| ring-hash | consistent hash (캐시 친화) |
| maglev | Google 의 consistent hash (재분배 최소) |
| locality-aware | 같은 zone / region 우선 |
Outlier detection :
- 각 백엔드 의 *최근 에러율 모니터링.
- 임계치 초과 시 *자동 차단 → 회복 후 다시 풀에 포함.
Circuit Breaker :
- 백엔드 의 *동시 연결 한도.
- 한도 초과 시 즉시 reject — 다른 백엔드 보호.
→ Ingress / Service 만으로 부족 한 *세밀한 정책 이 Service Mesh 의 가치.
4.3 Service Mesh 의 *비용
- Sidecar 가 *모든 Pod 에 추가 — RAM ~50MB / Pod.
- latency 증가 — 각 hop 마다 *0.5~1 ms 추가.
- 복잡도 증가 — 새 abstraction 학습.
→ 수십 ~ 수백 서비스 의 *상호 통신 정교화 가 필요 한 단계 부터 진지한 검토. 우리 6 노드 클러스터 에선 과잉.
5. 외부 LB — *클러스터 외부 의 *진입점**
5.1 Service Type 의 *4 종
spec:
type: ClusterIP # 기본 — 내부 만 접근
spec:
type: NodePort # 30000~32767 포트 노출 — 모든 노드 IP 에서
spec:
type: LoadBalancer # 외부 LB 자동 provision (클라우드) 또는 MetalLB
spec:
type: ExternalName # DNS CNAME — 외부 서비스 alias
5.2 온프렘 — *LoadBalancer 의 구현
클라우드 가 *type: LoadBalancer 를 자동 으로 클라우드 LB 생성 하지만, 온프렘 에선 *직접 구현 필요.
(1) MetalLB
[ARP / NDP mode] — Layer 2
- LAN 내 *VIP 발신*. ARP 응답 으로 *한 노드 가 *대표*.
- 한 노드 만 트래픽 처리 (fail-over 가능).
[BGP mode] — Layer 3
- 라우터 와 *BGP peering*.
- *진짜 ECMP 분산* — 모든 노드 가 트래픽 처리.
(2) Klipper-LB (K3s 기본)
K3s 의 *Servicelb. Pod 안 의 *HostPort 를 사용해 모든 노드 에 *type=LoadBalancer Service 의 port 노출.
- 간단. 클러스터 외부 가 *어느 노드 IP 로든 접근 가능.
- 진짜 LB 가 아니라 *DNAT 트릭 — 클라우드 LB 같은 *external IP 발급 없음.
(3) Cilium LB
Cilium CNI 가 *내장 LB 제공 — eBPF 기반.
- L4 + L7 모두 지원.
- 높은 성능 (eBPF kernel-level).
- MetalLB / kube-proxy 대체 가능.
5.3 클라우드 — *Managed LB
| 클라우드 | L4 | L7 |
|---|---|---|
| AWS | NLB (Network LB) | ALB (Application LB) |
| GCP | Network LB | HTTP(S) LB, Global LB |
| Azure | Standard LB | Application Gateway |
→ Service type=LoadBalancer + 적절한 annotation → 클라우드 가 *자동 provision.
6. 우리 6 노드 K3s 클러스터 — *실제 사용
위 도구 들 의 *어느 것 을 실제로 *쓰고 있는가.
6.1 현재 stack
[Internet]
↓
[Cloudflare Tunnel] ←─ 외부 진입점 *유일*. 클러스터 외부 노출 포트 *없음*
↓ TLS 종료, mutual auth
[ingress-nginx] ←─ L7 라우팅, *round-robin 기본*
↓ host header 기반 (jen.lemuel.co.kr → settlement-service)
[Service (ClusterIP)] ←─ L4, kube-proxy *iptables 모드*
↓ *확률 기반 랜덤 분산*
[Pod x 3] ←─ podAntiAffinity 로 david / louise / isagal 분산
6.2 우리 의 *흥미로운 선택들
(1) Cloudflare Tunnel = 사실상 L7 LB
Cloudflare 의 *전 세계 edge 가 우리 의 *외부 L7 LB. ingress-nginx 가 그 뒤 에서 내부 라우팅.
장점 :
- 외부 직접 노출 0 — 방화벽 완전 닫힘.
- Cloudflare 의 *DDoS 방어, WAF, rate limit 무료.
- TLS 인증서 자동 (Cloudflare).
(2) ingress-nginx (Traefik 안 씀)
- K3s 기본 은 Traefik. 하지만 우리는 *ingress-nginx 로 전환.
- 이유 : cert-manager 연동 의 *생태계 풍부, annotation 표준화, 경험 익숙.
(3) kube-proxy iptables 모드 (기본 그대로)
- IPVS 전환 안 함. 6 노드 규모 에선 *iptables 의 *룰 평가 부담 없음.
- 수백 Service 까지는 iptables 가 충분.
- 수천 Service 이상 되면 IPVS 권장.
(4) MetalLB / Klipper-LB 둘 다 사용 안 함
- Cloudflare Tunnel 이 *외부 진입 을 대신 함 → type=LoadBalancer Service 자체 가 불필요.
- 내부 서비스 는 *ClusterIP 면 충분.
(5) Service Mesh 없음
- 6 노드 규모 + *Cloudflare 외부 보안 → Istio 같은 mesh 의 *복잡도 / 비용 > 얻는 가치.
- 내부 통신 은 *LAN + Service ClusterIP 면 충분.
6.3 우리 의 *load balance 알고리즘 의 *실제**
| 계층 | 도구 | 알고리즘 |
|---|---|---|
| L7 (외부) | Cloudflare | Cloudflare 의 *자체 글로벌 LB (anycast + region 라우팅) |
| L7 (내부) | ingress-nginx | round-robin |
| L4 (Service) | kube-proxy iptables | 확률 기반 랜덤 (round-robin 아님!) |
→ *우리 의 *내부 분산 의 *실제 동작 은 “확률 랜덤”. 명시적 으로 round-robin 원하면 *IPVS 전환 필요.
7. 흔한 함정 — *5 가지
7.1 함정 1 — *“Service 가 round-robin 한다” 의 오해
- iptables 모드 = 확률 랜덤. round-robin 아님.
- IPVS 모드 = 진짜 round-robin.
- → kube-proxy mode 확인 후 *말할 것.
7.2 함정 2 — *Session affinity 의 *함정**
spec:
sessionAffinity: ClientIP
sessionAffinityConfig:
clientIP:
timeoutSeconds: 10800
- 클라이언트 IP 기반 sticky — NAT 뒤 의 *대규모 사용자 가 *같은 IP 로 보이면 → 모두 한 백엔드 로 집중.
- → cookie 기반 affinity (Ingress 레벨) 가 더 안전.
7.3 함정 3 — *Pod 가 *NOT_READY 인데 트래픽 받음**
- kube-proxy 가 readiness probe 확인 안 함.
- Endpoint controller 가 *not-ready Pod 을 *endpoints 에서 제거 — 이게 느리면 (1~2초) 그 사이 *트래픽 일부 실패.
- → graceful shutdown (
terminationGracePeriodSeconds+preStophook) + readiness probe 정확.
7.4 함정 4 — *Ingress controller pod 가 *어디 도나
- 1 개 만 도는 single point of failure.
- DaemonSet 으로 모든 노드 또는 *replicas 3+ * 추천.
7.5 함정 5 — *Long-lived connection 의 *불균등 분산
- HTTP/2, gRPC, WebSocket = 한 connection 으로 *수많은 request.
- round-robin 이 connection 단위. long-lived connection 한 개 가 *대부분 트래픽 흡수 — 불균등.
- → least-request 또는 *gRPC-aware LB (Envoy) 권장.
8. 알고리즘 선택 가이드
8.1 언제 *round-robin 으로 *충분 한가
- 동질 적 워크로드 (모든 Pod 같은 spec, 같은 부하).
- 짧은 request (REST API).
- 상태 없음.
8.2 언제 *least-connection 이 *필요 한가
- long-lived connection (WebSocket, SSE, DB connection pool).
- request 처리 시간 *변동 큼.
8.3 언제 *consistent hash 가 *필요 한가
- 캐시 친화 워크로드 — 같은 키 → 같은 백엔드 → 캐시 hit.
- DB connection pool 분산.
8.4 언제 *sticky session 이 *필요 한가
- 세션 정보 가 *백엔드 메모리 에 *상태 — 외부 store (Redis) 로 빼면 불필요.
- legacy 애플리케이션.
- → 가능하면 *stateless 로 만들고 세션 외부화. sticky 는 최후 수단.
9. 결론 — *같은 단어 가 *다른 구현
“K8s 가 load balance 한다” 는 반쪽 진실. L4 / L7, kube-proxy mode, Ingress controller, Service Mesh 의 각 계층 마다 *다른 도구 가 다른 알고리즘 으로 load balance.
오늘 정리한 진실 :
- kube-proxy iptables = 확률 랜덤. round-robin 아님.
- kube-proxy IPVS = round-robin + 8 종 알고리즘.
- nginx-ingress = round-robin.
- Traefik = weighted round-robin.
- Service Mesh (Envoy) = 수십 가지 알고리즘 + outlier detection + circuit breaker.
- 외부 LB = 클라우드 가 자동 / 온프렘 은 MetalLB / Cilium / Klipper-LB.
어느 계층 / 어느 도구 / 어느 알고리즘 을 선택 할지 는 워크로드 의 *분포 / 세션 특성 / 외부 노출 요구 / 클러스터 규모 의 함수. “기본값 로 갈래” 의 *기본값 이 *iptables 의 확률 랜덤 이라는 사실 만 알면 대부분의 사고 를 예방.
우리 6 노드 K3s 클러스터 의 현재 stack (Cloudflare Tunnel + ingress-nginx + kube-proxy iptables + ClusterIP Service + podAntiAffinity) 가 내 규모 에 맞는 *최소-필수 의 *균형. 수십~수백 서비스 가 되면 *IPVS 전환 + Service Mesh 도입 의 진지한 검토 시점.
Load balance 의 *진짜 깊이 는 “어떤 알고리즘 인가” 가 아니라 “내 워크로드 에 *어떤 알고리즘 이 *적합 한가” 의 측정 과 선택. 그게 *시니어 엔지니어 의 *네트워크 적 사고.
참고
- Kubernetes 공식 문서 — Service : kubernetes.io/docs/concepts/services-networking/service.
- Kubernetes 공식 문서 — Ingress : kubernetes.io/docs/concepts/services-networking/ingress.
- IPVS 공식 — linuxvirtualserver.org.
- Envoy Proxy 공식 문서 — load balancing algorithms.
- Cilium docs — eBPF Datapath.
- Brendan Burns et al., Kubernetes: Up and Running, 3rd ed.
- Liz Rice, Container Networking — L4 / L7 의 깊이.
- 자매편 :
- K8s 컨테이너 오케스트레이션 전쟁사
- K8s 의 유용성 — 온프레미스 vs 클라우드
- 논블로킹 I/O 서버 — L4 의 *epoll 깊이
- 보안 의 7 기둥 — 방화벽 / Zero Trust 의 LB 통합